 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-based Label Smoothing For Better Calibrated Classification Networks
Paper and Code
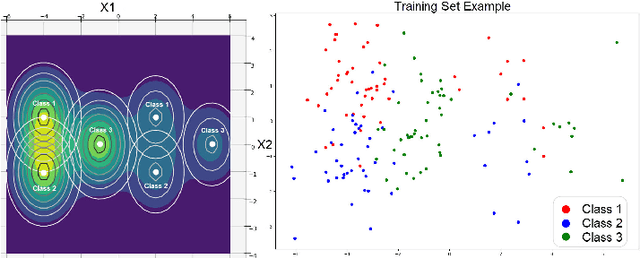
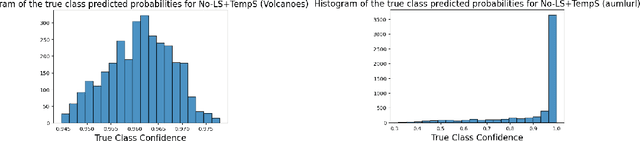
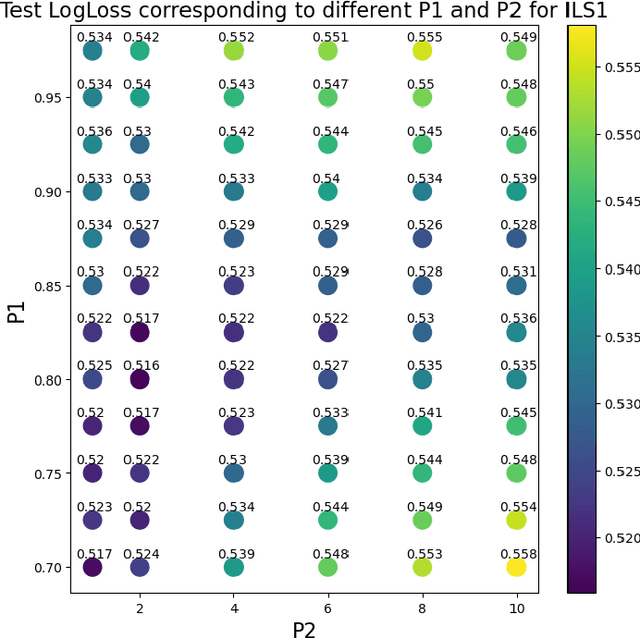
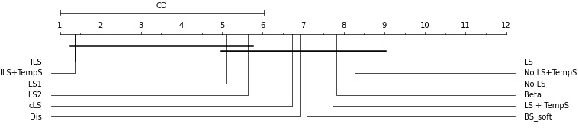
Label smoothing is widely used in deep neural networks for multi-class classification. While it enhances model generalization and reduces overconfidence by aiming to lower the probability for the predicted class, it distorts the predicted probabilities of other classes resulting in poor class-wise calibration. Another method for enhancing model generalization is self-distillation where the predictions of a teacher network trained with one-hot labels are used as the target for training a student network. We take inspiration from both label smoothing and self-distillation and propose two novel instance-based label smoothing approaches, where a teacher network trained with hard one-hot labels is used to determine the amount of per class smoothness applied to each instance. The assigned smoothing factor is non-uniformly distributed along with the classes according to their similarity with the actual class. Our methods show better generalization and calibration over standard label smoothing on various deep neural architectures and image classification datasets.