 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINSPIRED2: An Improved Dataset for Sociable Conversational Recommendation
Paper and Code

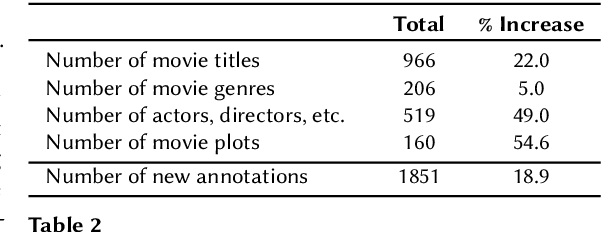

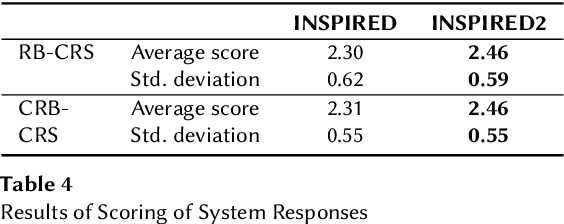
Conversational recommender systems (CRS) that interact with users in natural language utilize recommendation dialogs collected with the help of paired humans, where one plays the role of a seeker and the other as a recommender. These recommendation dialogs include items and entities to disclose seekers' preferences in natural language. However, in order to precisely model the seekers' preferences and respond consistently, mainly CRS rely on explicitly annotated items and entities that appear in the dialog, and usually leverage the domain knowledge. In this work, we investigate INSPIRED, a dataset consisting of recommendation dialogs for the sociable conversational recommendation, where items and entities were explicitly annotated using automatic keyword or pattern matching techniques. To this end, we found a large number of cases where items and entities were either wrongly annotated or missing annotations at all. The question however remains to what extent automatic techniques for annotations are effective. Moreover, it is unclear what is the relative impact of poor and improved annotations on the overall effectiveness of a CRS in terms of the consistency and quality of responses. In this regard, first, we manually fixed the annotations and removed the noise in the INSPIRED dataset. Second, we evaluate the performance of several benchmark CRS using both versions of the dataset. Our analyses suggest that with the improved version of the dataset, i.e., INSPIRED2, various benchmark CRS outperformed and that dialogs are rich in knowledge concepts compared to when the original version is used. We release our improved dataset (INSPIRED2) publicly at https://github.com/ahtsham58/INSPIRED2.