 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsights into Analogy Completion from the Biomedical Domain
Paper and Code

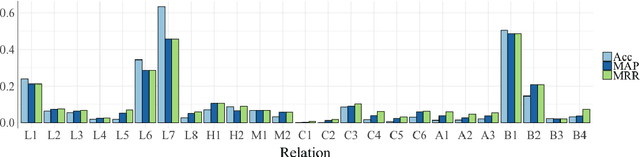


Analogy completion has been a popular task in recent years for evaluating the semantic properties of word embeddings, but the standard methodology makes a number of assumptions about analogies that do not always hold, either in recent benchmark datasets or when expanding into other domains. Through an analysis of analogies in the biomedical domain, we identify three assumptions: that of a Single Answer for any given analogy, that the pairs involved describe the Same Relationship, and that each pair is Informative with respect to the other. We propose modifying the standard methodology to relax these assumptions by allowing for multiple correct answers, reporting MAP and MRR in addition to accuracy, and using multiple example pairs. We further present BMASS, a novel dataset for evaluating linguistic regularities in biomedical embeddings, and demonstrate that the relationships described in the dataset pose significant semantic challenges to current word embedding methods.