 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInjective Domain Knowledge in Neural Networks for Transprecision Computing
Paper and Code
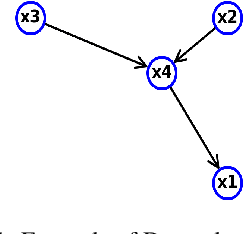
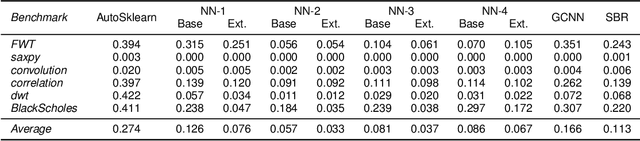

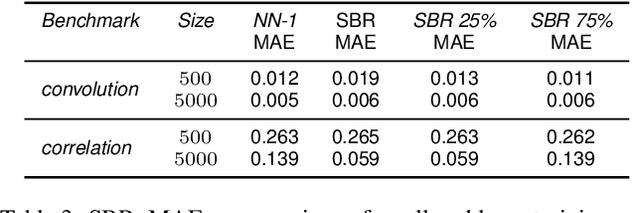
Machine Learning (ML) models are very effective in many learning tasks, due to the capability to extract meaningful information from large data sets. Nevertheless, there are learning problems that cannot be easily solved relying on pure data, e.g. scarce data or very complex functions to be approximated. Fortunately, in many contexts domain knowledge is explicitly available and can be used to train better ML models. This paper studies the improvements that can be obtained by integrating prior knowledge when dealing with a non-trivial learning task, namely precision tuning of transprecision computing applications. The domain information is injected in the ML models in different ways: I) additional features, II) ad-hoc graph-based network topology, III) regularization schemes. The results clearly show that ML models exploiting problem-specific information outperform the purely data-driven ones, with an average accuracy improvement around 38%.