 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-Theoretic Representation Learning for Positive-Unlabeled Classification
Paper and Code
Feb 12, 2018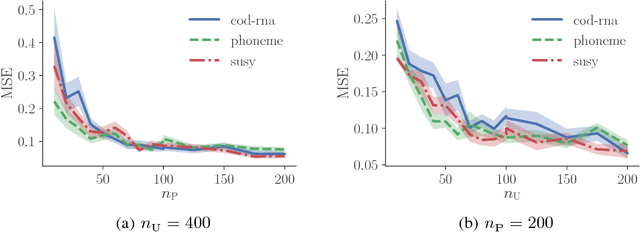
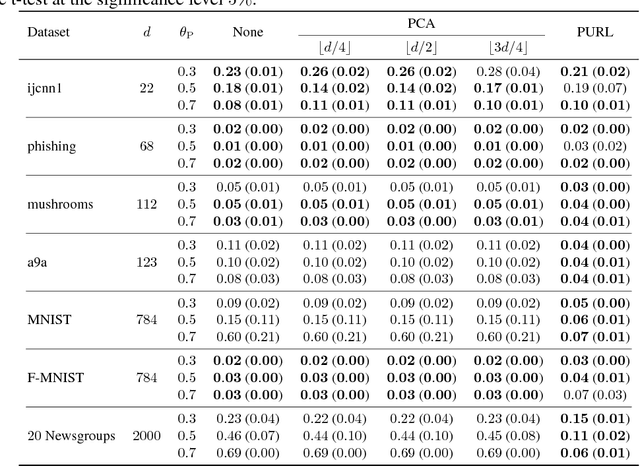


Recent advances in weakly supervised classification allow us to train a classifier only from positive and unlabeled (PU) data. However, existing PU classification methods typically require an accurate estimate of the class-prior probability, which is a critical bottleneck particularly for high-dimensional data. This problem has been commonly addressed by applying principal component analysis in advance, but such unsupervised dimension reduction can collapse underlying class structure. In this paper, we propose a novel representation learning method from PU data based on the information-maximization principle. Our method does not require class-prior estimation and thus can be used as a preprocessing method for PU classification. Through experiments, we demonstrate that our method combined with deep neural networks highly improves the accuracy of PU class-prior estimation, leading to state-of-the-art PU classification performance.