 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation theoretic limits of learning a sparse rule
Paper and Code
Jun 19, 2020

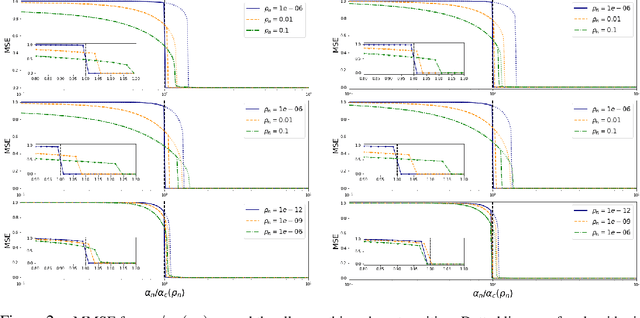
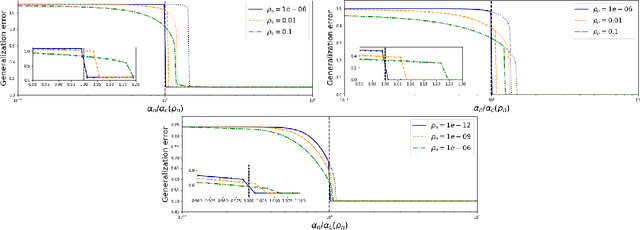
We consider generalized linear models in regimes where the number of nonzerocomponents of the signal and accessible data points are sublinear with respect to the size of the signal. We prove a variational formula for the asymptotic mutual information per sample when the system size grows to infinity. This result allows us to heuristically derive an expression for the minimum mean-square error (MMSE)of the Bayesian estimator. We then find that, for discrete signals and suitable vanishing scalings of the sparsity and sampling rate, the MMSE displays an all-or-nothing phenomenon, namely, the MMSE sharply jumps from its maximum value to zero at a critical sampling rate. The all-or-nothing phenomenon has recently been proved to occur in high-dimensional linear regression. Our analysis goes beyond the linear case and applies to learning the weights of a perceptron with general activation function in a teacher-student scenario. In particular we discuss an all-or-nothing phenomenon for the generalization error with a sublinear set of training examples.