 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Theoretic Limits of Data Shuffling for Distributed Learning
Paper and Code
Sep 16, 2016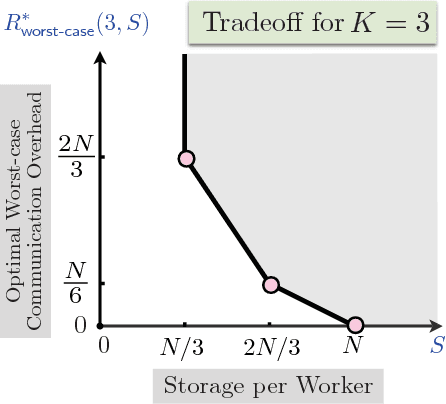
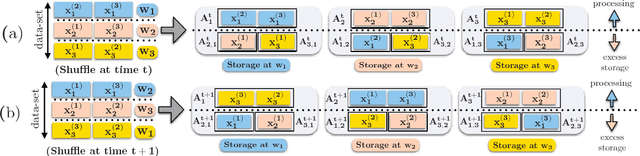
Data shuffling is one of the fundamental building blocks for distributed learning algorithms, that increases the statistical gain for each step of the learning process. In each iteration, different shuffled data points are assigned by a central node to a distributed set of workers to perform local computations, which leads to communication bottlenecks. The focus of this paper is on formalizing and understanding the fundamental information-theoretic trade-off between storage (per worker) and the worst-case communication overhead for the data shuffling problem. We completely characterize the information theoretic trade-off for $K=2$, and $K=3$ workers, for any value of storage capacity, and show that increasing the storage across workers can reduce the communication overhead by leveraging coding. We propose a novel and systematic data delivery and storage update strategy for each data shuffle iteration, which preserves the structural properties of the storage across the workers, and aids in minimizing the communication overhead in subsequent data shuffling iterations.