 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInductive Bias of Multi-Channel Linear Convolutional Networks with Bounded Weight Norm
Paper and Code
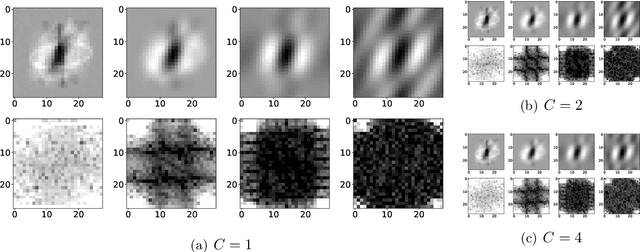

We study the function space characterization of the inductive bias resulting from controlling the $\ell_2$ norm of the weights in linear convolutional networks. We view this in terms of an induced regularizer in the function space given by the minimum norm of weights required to realize a linear function. For two layer linear convolutional networks with $C$ output channels and kernel size $K$, we show the following: (a) If the inputs to the network have a single channel, the induced regularizer for any $K$ is a norm given by a semidefinite program (SDP) that is independent of the number of output channels $C$. We further validate these results through a binary classification task on MNIST. (b) In contrast, for networks with multi-channel inputs, multiple output channels can be necessary to merely realize all matrix-valued linear functions and thus the inductive bias does depend on $C$. Further, for sufficiently large $C$, the induced regularizer for $K=1$ and $K=D$ are the nuclear norm and the $\ell_{2,1}$ group-sparse norm, respectively, of the Fourier coefficients -- both of which promote sparse structures.