 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndian Buffet Neural Networks for Continual Learning
Paper and Code
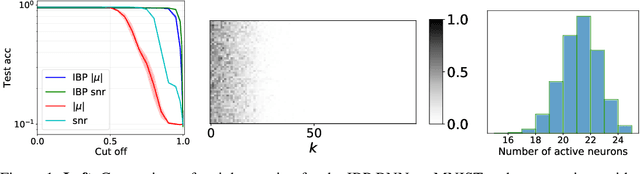
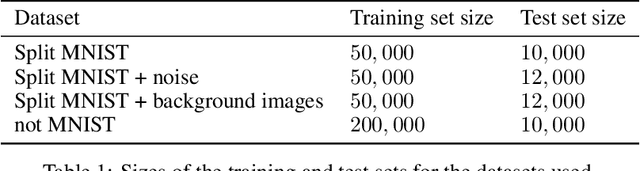
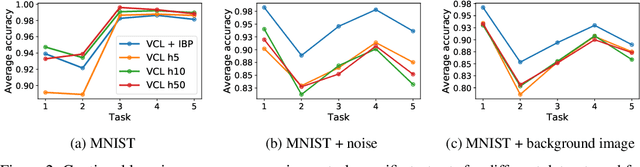
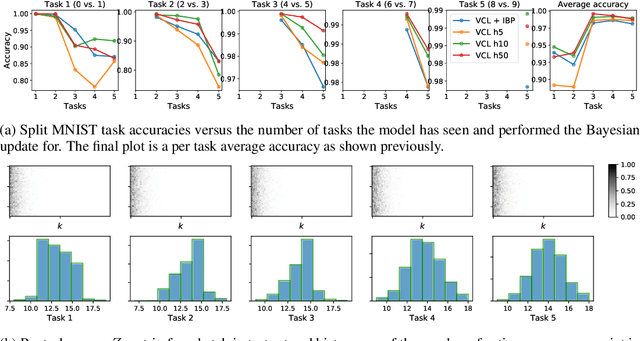
We place an Indian Buffet Process (IBP) prior over the neural structure of a Bayesian Neural Network (BNN), thus allowing the complexity of the BNN to increase and decrease automatically. We apply this methodology to the problem of resource allocation in continual learning, where new tasks occur and the network requires extra resources. Our BNN exploits online variational inference with relaxations to the Bernoulli and Beta distributions (which constitute the IBP prior), so allowing the use of the reparameterisation trick to learn variational posteriors via gradient-based methods. As we automatically learn the number of weights in the BNN, overfitting and underfitting problems are largely overcome. We show empirically that the method offers competitive results compared to Variational Continual Learning (VCL) in some settings.