 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Explicit Uncertainty Estimates into Deep Offline Reinforcement Learning
Paper and Code
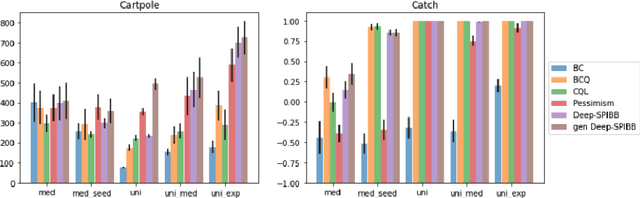

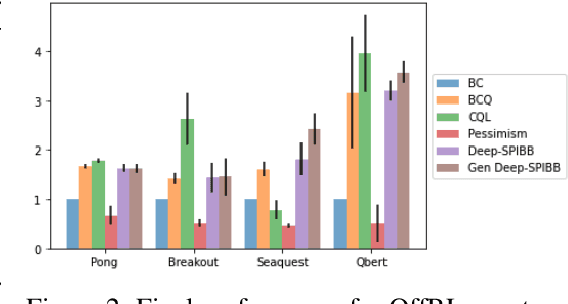

Most theoretically motivated work in the offline reinforcement learning setting requires precise uncertainty estimates. This requirement restricts the algorithms derived in that work to the tabular and linear settings where such estimates exist. In this work, we develop a novel method for incorporating scalable uncertainty estimates into an offline reinforcement learning algorithm called deep-SPIBB that extends the SPIBB family of algorithms to environments with larger state and action spaces. We use recent innovations in uncertainty estimation from the deep learning community to get more scalable uncertainty estimates to plug into deep-SPIBB. While these uncertainty estimates do not allow for the same theoretical guarantees as in the tabular case, we argue that the SPIBB mechanism for incorporating uncertainty is more robust and flexible than pessimistic approaches that incorporate the uncertainty as a value function penalty. We bear this out empirically, showing that deep-SPIBB outperforms pessimism based approaches with access to the same uncertainty estimates and performs at least on par with a variety of other strong baselines across several environments and datasets.