 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Attribution Importance for Improving Faithfulness Metrics
Paper and Code


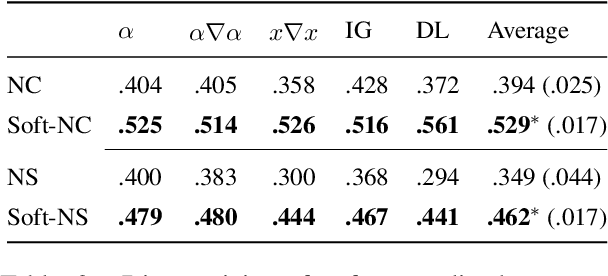

Feature attribution methods (FAs) are popular approaches for providing insights into the model reasoning process of making predictions. The more faithful a FA is, the more accurately it reflects which parts of the input are more important for the prediction. Widely used faithfulness metrics, such as sufficiency and comprehensiveness use a hard erasure criterion, i.e. entirely removing or retaining the top most important tokens ranked by a given FA and observing the changes in predictive likelihood. However, this hard criterion ignores the importance of each individual token, treating them all equally for computing sufficiency and comprehensiveness. In this paper, we propose a simple yet effective soft erasure criterion. Instead of entirely removing or retaining tokens from the input, we randomly mask parts of the token vector representations proportionately to their FA importance. Extensive experiments across various natural language processing tasks and different FAs show that our soft-sufficiency and soft-comprehensiveness metrics consistently prefer more faithful explanations compared to hard sufficiency and comprehensiveness. Our code: https://github.com/casszhao/SoftFaith