 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Learning with Representations: Contextual Generalization of Trained Transformers
Paper and Code
Aug 19, 2024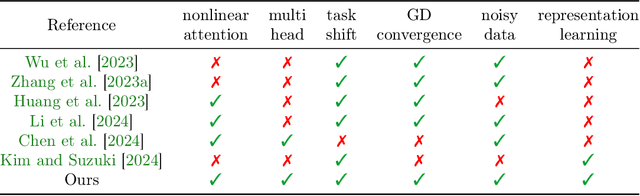



In-context learning (ICL) refers to a remarkable capability of pretrained large language models, which can learn a new task given a few examples during inference. However, theoretical understanding of ICL is largely under-explored, particularly whether transformers can be trained to generalize to unseen examples in a prompt, which will require the model to acquire contextual knowledge of the prompt for generalization. This paper investigates the training dynamics of transformers by gradient descent through the lens of non-linear regression tasks. The contextual generalization here can be attained via learning the template function for each task in-context, where all template functions lie in a linear space with $m$ basis functions. We analyze the training dynamics of one-layer multi-head transformers to in-contextly predict unlabeled inputs given partially labeled prompts, where the labels contain Gaussian noise and the number of examples in each prompt are not sufficient to determine the template. Under mild assumptions, we show that the training loss for a one-layer multi-head transformer converges linearly to a global minimum. Moreover, the transformer effectively learns to perform ridge regression over the basis functions. To our knowledge, this study is the first provable demonstration that transformers can learn contextual (i.e., template) information to generalize to both unseen examples and tasks when prompts contain only a small number of query-answer pairs.