 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImputing Missing Boarding Stations With Machine Learning Methods
Paper and Code
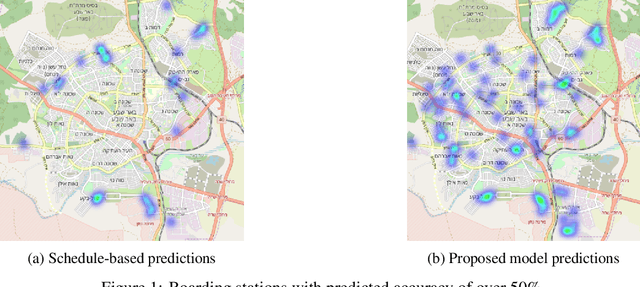
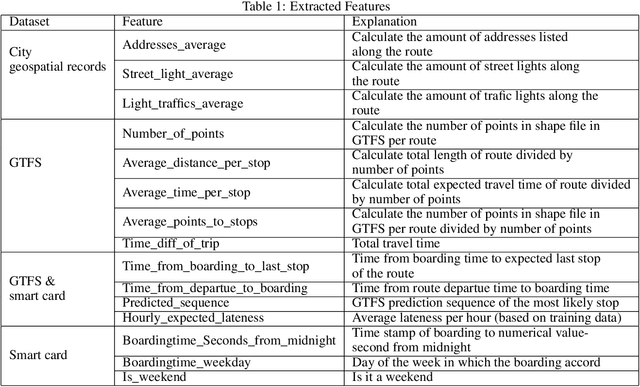
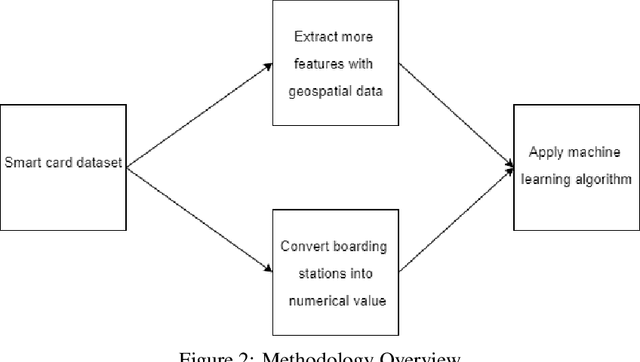

With the increase in population densities and environmental awareness, public transport has become an important aspect of urban life. Consequently, large quantities of transportation data are generated, and mining data from smart card use has become a standardized method to understand the travel habits of passengers. Public transport datasets, however, often may lack data integrity; boarding stop information may be missing due to either imperfect acquirement processes or inadequate reporting. As a result, large quantities of observations and even complete sections of cities might be absent from the smart card database. We have developed a machine (supervised) learning method to impute missing boarding stops based on ordinal classification. In addition, we present a new metric, Pareto Accuracy, to evaluate algorithms where classes have an ordinal nature. Results are based on a case study in the Israeli city of Beer Sheva for one month of data. We show that our proposed method significantly notably outperforms current imputation methods and can improve the accuracy and usefulness of large-scale transportation data.