 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Visual Grounding by Encouraging Consistent Gradient-based Explanations
Paper and Code
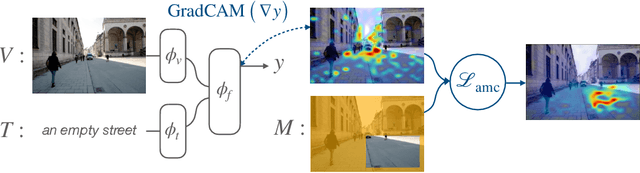
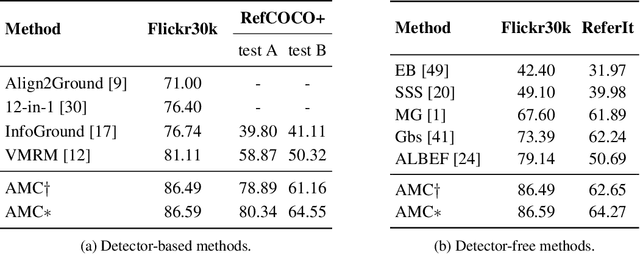
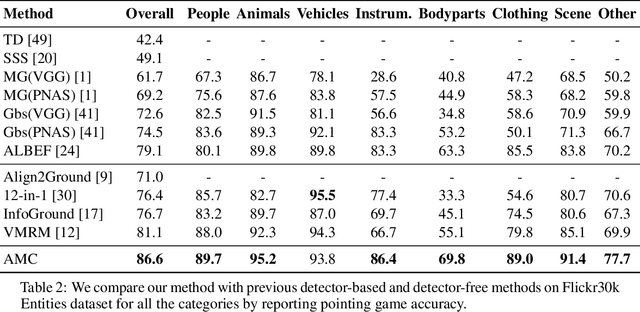

We propose a margin-based loss for vision-language model pretraining that encourages gradient-based explanations that are consistent with region-level annotations. We refer to this objective as Attention Mask Consistency (AMC) and demonstrate that it produces superior visual grounding performance compared to models that rely instead on region-level annotations for explicitly training an object detector such as Faster R-CNN. AMC works by encouraging gradient-based explanation masks that focus their attention scores mostly within annotated regions of interest for images that contain such annotations. Particularly, a model trained with AMC on top of standard vision-language modeling objectives obtains a state-of-the-art accuracy of 86.59% in the Flickr30k visual grounding benchmark, an absolute improvement of 5.48% when compared to the best previous model. Our approach also performs exceedingly well on established benchmarks for referring expression comprehension and offers the added benefit by design of gradient-based explanations that better align with human annotations.