 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the repeatability of deep learning models with Monte Carlo dropout
Paper and Code
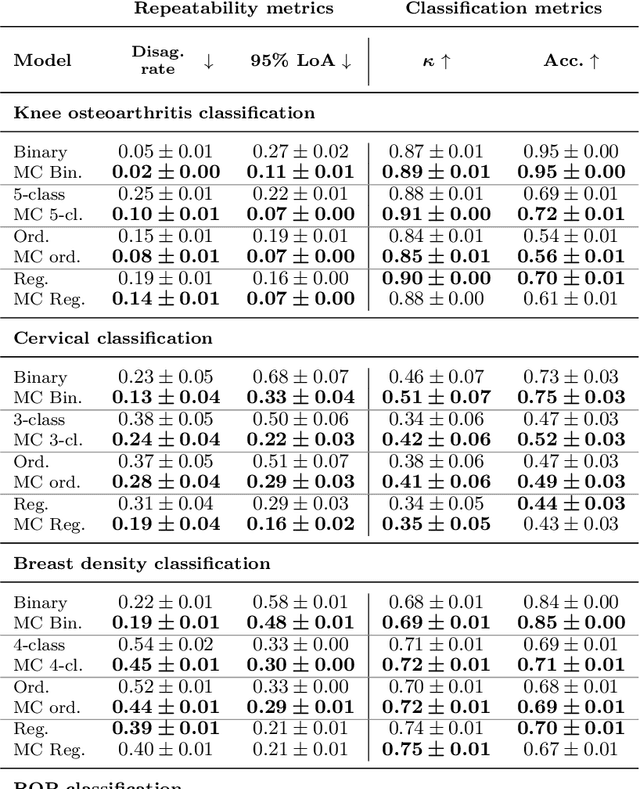
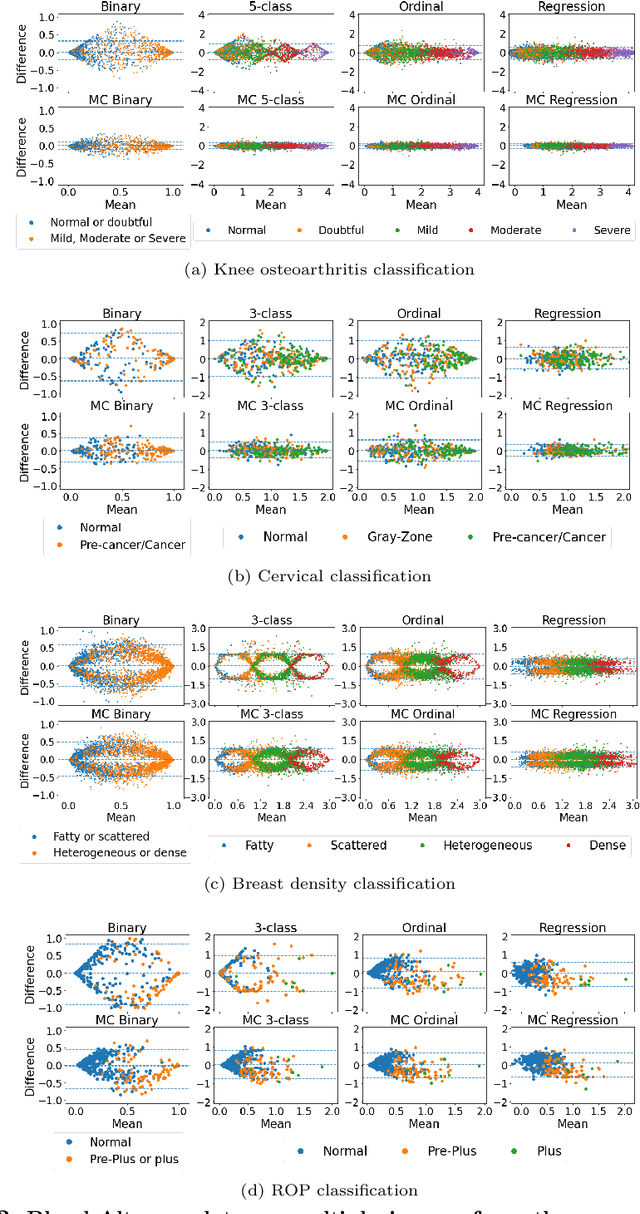
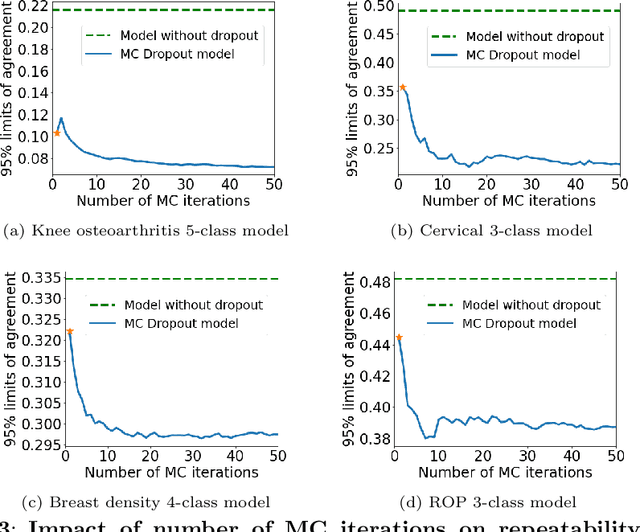
The integration of artificial intelligence into clinical workflows requires reliable and robust models. Repeatability is a key attribute of model robustness. Repeatable models output predictions with low variation during independent tests carried out under similar conditions. During model development and evaluation, much attention is given to classification performance while model repeatability is rarely assessed, leading to the development of models that are unusable in clinical practice. In this work, we evaluate the repeatability of four model types (binary classification, multi-class classification, ordinal classification, and regression) on images that were acquired from the same patient during the same visit. We study the performance of binary, multi-class, ordinal, and regression models on four medical image classification tasks from public and private datasets: knee osteoarthritis, cervical cancer screening, breast density estimation, and retinopathy of prematurity. Repeatability is measured and compared on ResNet and DenseNet architectures. Moreover, we assess the impact of sampling Monte Carlo dropout predictions at test time on classification performance and repeatability. Leveraging Monte Carlo predictions significantly increased repeatability for all tasks on the binary, multi-class, and ordinal models leading to an average reduction of the 95\% limits of agreement by 16% points and of the disagreement rate by 7% points. The classification accuracy improved in most settings along with the repeatability. Our results suggest that beyond about 20 Monte Carlo iterations, there is no further gain in repeatability. In addition to the higher test-retest agreement, Monte Carlo predictions were better calibrated which leads to output probabilities reflecting more accurately the true likelihood of being correctly classified.