 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the convergence of SGD through adaptive batch sizes
Paper and Code

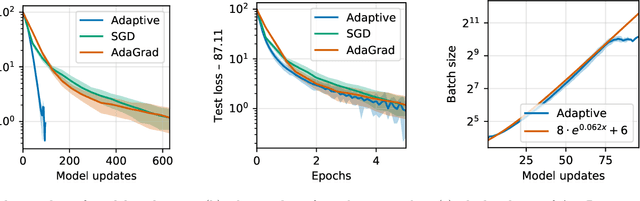
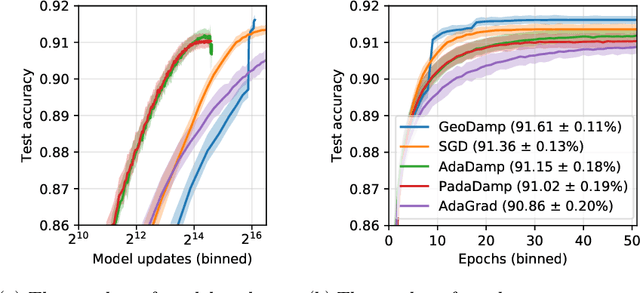
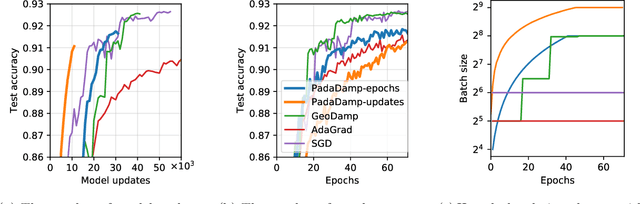
Mini-batch stochastic gradient descent (SGD) approximates the gradient of an objective function with the average gradient of some batch of constant size. While small batch sizes can yield high-variance gradient estimates that prevent the model from learning a good model, large batches may require more data and computational effort. This work presents a method to change the batch size adaptively with model quality. We show that our method requires the same number of model updates as full-batch gradient descent while requiring the same total number of gradient computations as SGD. While this method requires evaluating the objective function, we present a passive approximation that eliminates this constraint and improves computational efficiency. We provide extensive experiments illustrating that our methods require far fewer model updates without increasing the total amount of computation.