 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Robustness via Tilted Exponential Layer: A Communication-Theoretic Perspective
Paper and Code
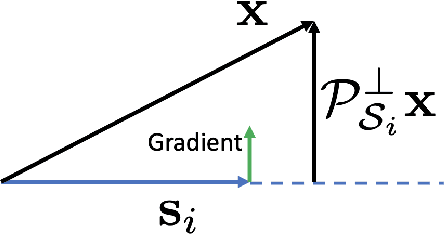
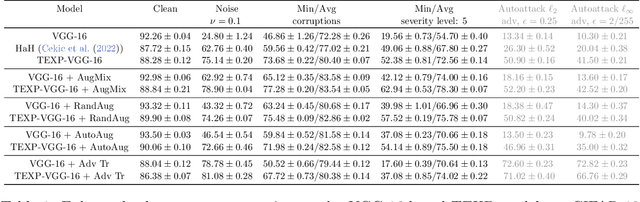
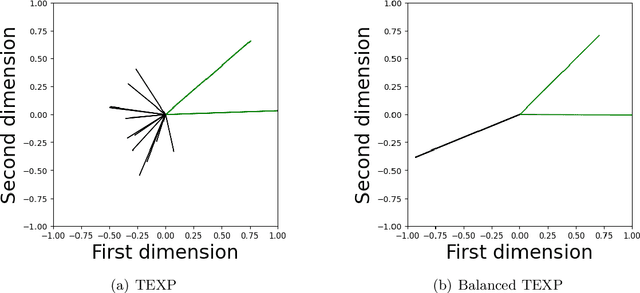
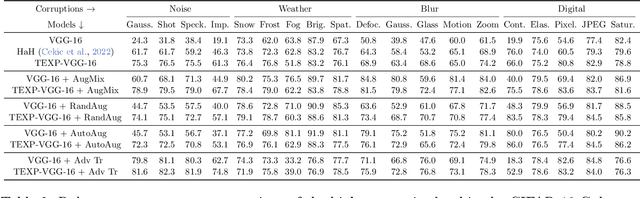
State-of-the-art techniques for enhancing robustness of deep networks mostly rely on empirical risk minimization with suitable data augmentation. In this paper, we propose a complementary approach motivated by communication theory, aimed at enhancing the signal-to-noise ratio at the output of a neural network layer via neural competition during learning and inference. In addition to minimization of a standard end-to-end cost, neurons compete to sparsely represent layer inputs by maximization of a tilted exponential (TEXP) objective function for the layer. TEXP learning can be interpreted as maximum likelihood estimation of matched filters under a Gaussian model for data noise. Inference in a TEXP layer is accomplished by replacing batch norm by a tilted softmax, which can be interpreted as computation of posterior probabilities for the competing signaling hypotheses represented by each neuron. After providing insights via simplified models, we show, by experimentation on standard image datasets, that TEXP learning and inference enhances robustness against noise and other common corruptions, without requiring data augmentation. Further cumulative gains in robustness against this array of distortions can be obtained by appropriately combining TEXP with data augmentation techniques.