 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Robustness In Speaker Identification Using A Two-Stage Attention Model
Paper and Code
Sep 24, 2019
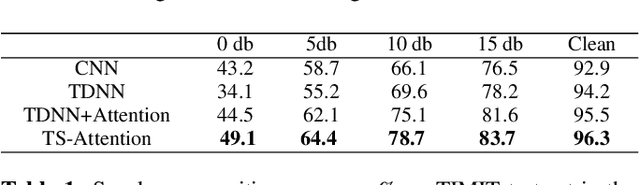
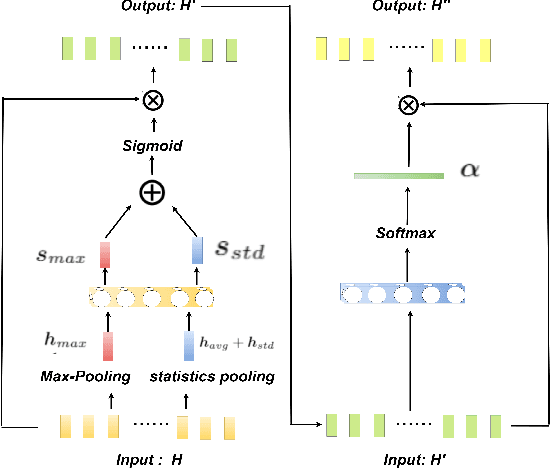

In this paper a novel framework to tackle speaker recognition using a two-stage attention model is proposed. In recent years, the use of deep neural networks, such as time delay neural network (TDNN), and attention model have boosted speaker recognition performance. However, it is still a challenging task to tackle speaker recognition in severe acoustic environments. To build a robust speaker recognition system against noise, we employ a two-stage attention model and combine it with a TDNN model. In this framework, the attention mechanism is used in two aspects: embedding space and temporal space. The embedding attention model built in embedding space is to highlight the importance of each embedding element by weighting them using self attention. The frame attention model built in temporal space aims to find which frames are significant for speaker recognition. To evaluate the effectiveness and robustness of our approach, we use the TIMIT dataset and test our approach in the condition of five kinds of noise and different signal-noise-ratios (SNRs). In comparison with three strong baselines, CNN, TDNN and TDNN+attention, the experimental results show that the use of our approach outperforms them in different conditions. The correct recognition rate obtained using our approach can still reach 49.1%, better than any baselines, even if the noise is Gaussian white Noise and the SNR is 0dB.