 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Multimodal Emotion Recognition by Leveraging Acoustic Adaptation and Visual Alignment
Paper and Code
Sep 10, 2024


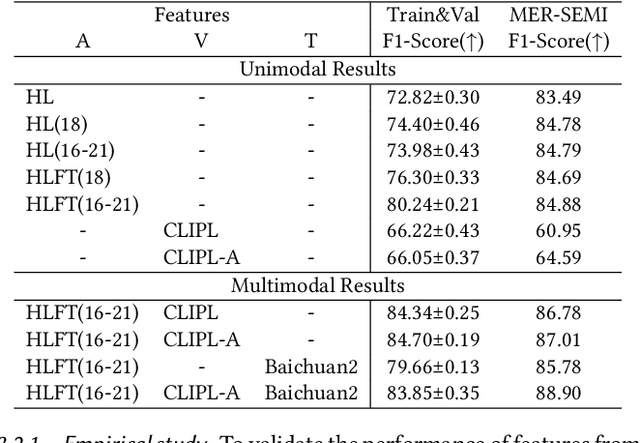
Multimodal Emotion Recognition (MER) aims to automatically identify and understand human emotional states by integrating information from various modalities. However, the scarcity of annotated multimodal data significantly hinders the advancement of this research field. This paper presents our solution for the MER-SEMI sub-challenge of MER 2024. First, to better adapt acoustic modality features for the MER task, we experimentally evaluate the contributions of different layers of the pre-trained speech model HuBERT in emotion recognition. Based on these observations, we perform Parameter-Efficient Fine-Tuning (PEFT) on the layers identified as most effective for emotion recognition tasks, thereby achieving optimal adaptation for emotion recognition with a minimal number of learnable parameters. Second, leveraging the strengths of the acoustic modality, we propose a feature alignment pre-training method. This approach uses large-scale unlabeled data to train a visual encoder, thereby promoting the semantic alignment of visual features within the acoustic feature space. Finally, using the adapted acoustic features, aligned visual features, and lexical features, we employ an attention mechanism for feature fusion. On the MER2024-SEMI test set, the proposed method achieves a weighted F1 score of 88.90%, ranking fourth among all participating teams, validating the effectiveness of our approach.