 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Monocular Depth Estimation by Leveraging Structural Awareness and Complementary Datasets
Paper and Code
Jul 22, 2020
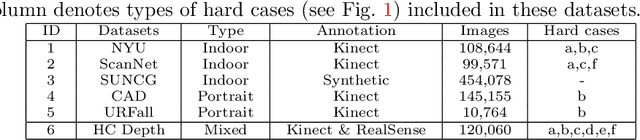
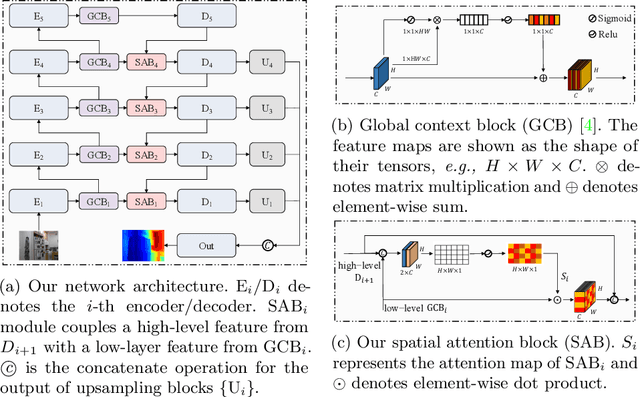
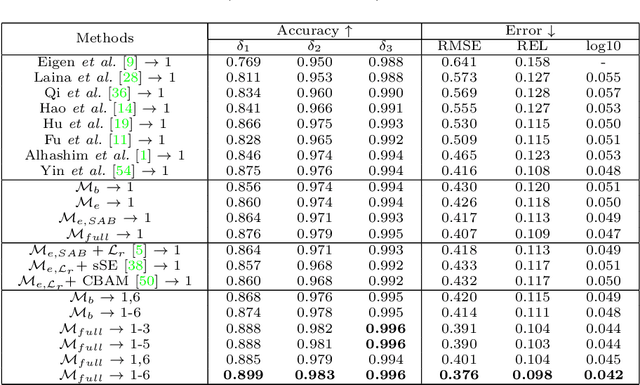
Monocular depth estimation plays a crucial role in 3D recognition and understanding. One key limitation of existing approaches lies in their lack of structural information exploitation, which leads to inaccurate spatial layout, discontinuous surface, and ambiguous boundaries. In this paper, we tackle this problem in three aspects. First, to exploit the spatial relationship of visual features, we propose a structure-aware neural network with spatial attention blocks. These blocks guide the network attention to global structures or local details across different feature layers. Second, we introduce a global focal relative loss for uniform point pairs to enhance spatial constraint in the prediction, and explicitly increase the penalty on errors in depth-wise discontinuous regions, which helps preserve the sharpness of estimation results. Finally, based on analysis of failure cases for prior methods, we collect a new Hard Case (HC) Depth dataset of challenging scenes, such as special lighting conditions, dynamic objects, and tilted camera angles. The new dataset is leveraged by an informed learning curriculum that mixes training examples incrementally to handle diverse data distributions. Experimental results show that our method outperforms state-of-the-art approaches by a large margin in terms of both prediction accuracy on NYUDv2 dataset and generalization performance on unseen datasets.