 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Model Training via Self-learned Label Representations
Paper and Code

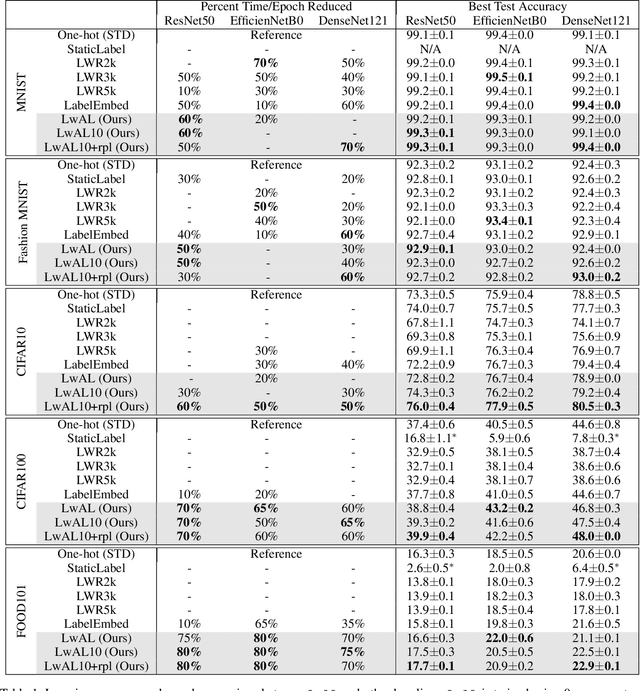
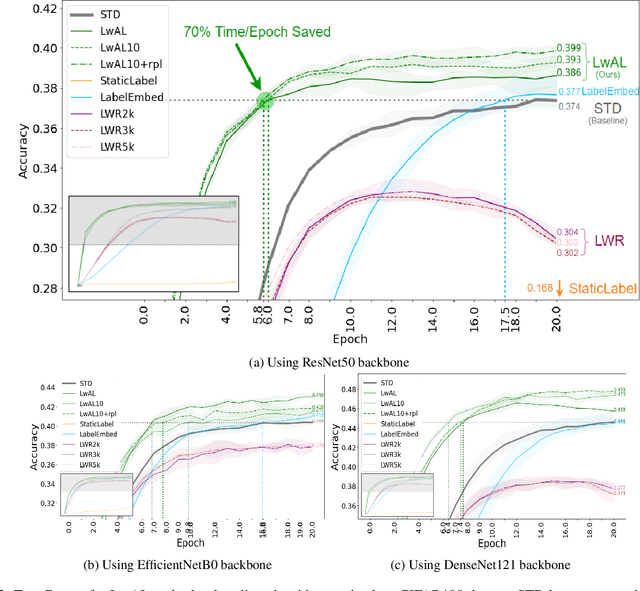

Modern neural network architectures have shown remarkable success in several large-scale classification and prediction tasks. Part of the success of these architectures is their flexibility to transform the data from the raw input representations (e.g. pixels for vision tasks, or text for natural language processing tasks) to one-hot output encoding. While much of the work has focused on studying how the input gets transformed to the one-hot encoding, very little work has examined the effectiveness of these one-hot labels. In this work, we demonstrate that more sophisticated label representations are better for classification than the usual one-hot encoding. We propose Learning with Adaptive Labels (LwAL) algorithm, which simultaneously learns the label representation while training for the classification task. These learned labels can significantly cut down on the training time (usually by more than 50%) while often achieving better test accuracies. Our algorithm introduces negligible additional parameters and has a minimal computational overhead. Along with improved training times, our learned labels are semantically meaningful and can reveal hierarchical relationships that may be present in the data.