 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving mitosis detection on histopathology images using large vision-language models
Paper and Code
Oct 11, 2023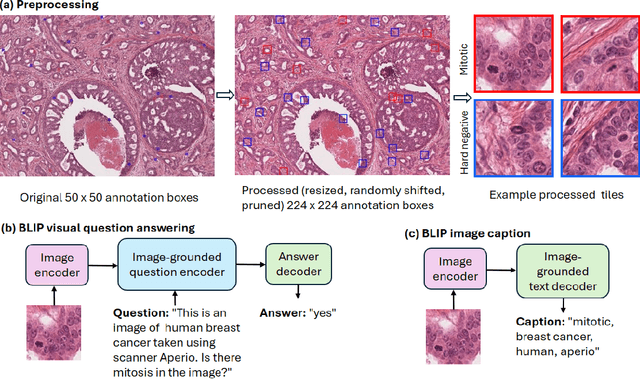
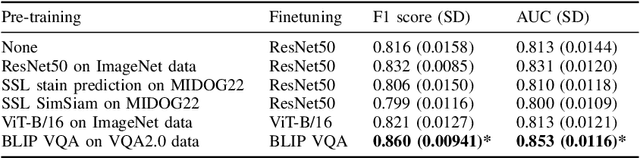

In certain types of cancerous tissue, mitotic count has been shown to be associated with tumor proliferation, poor prognosis, and therapeutic resistance. Due to the high inter-rater variability of mitotic counting by pathologists, convolutional neural networks (CNNs) have been employed to reduce the subjectivity of mitosis detection in hematoxylin and eosin (H&E)-stained whole slide images. However, most existing models have performance that lags behind expert panel review and only incorporate visual information. In this work, we demonstrate that pre-trained large-scale vision-language models that leverage both visual features and natural language improve mitosis detection accuracy. We formulate the mitosis detection task as an image captioning task and a visual question answering (VQA) task by including metadata such as tumor and scanner types as context. The effectiveness of our pipeline is demonstrated via comparison with various baseline models using 9,501 mitotic figures and 11,051 hard negatives (non-mitotic figures that are difficult to characterize) from the publicly available Mitosis Domain Generalization Challenge (MIDOG22) dataset.