 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving MAE against CCE under Label Noise
Paper and Code
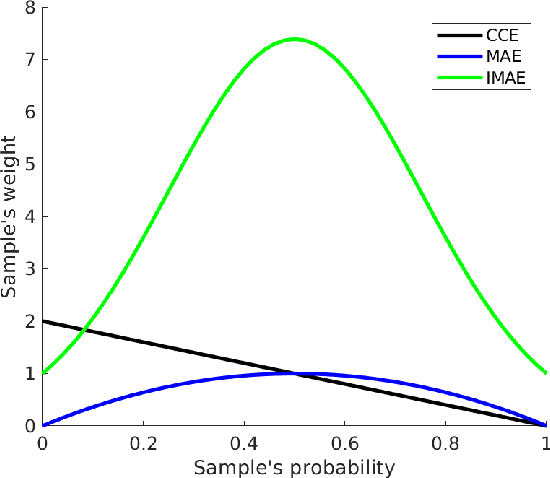
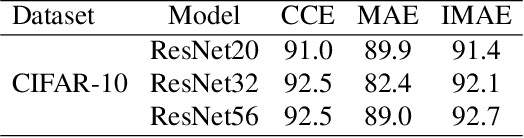
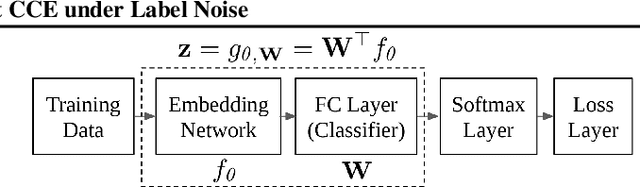
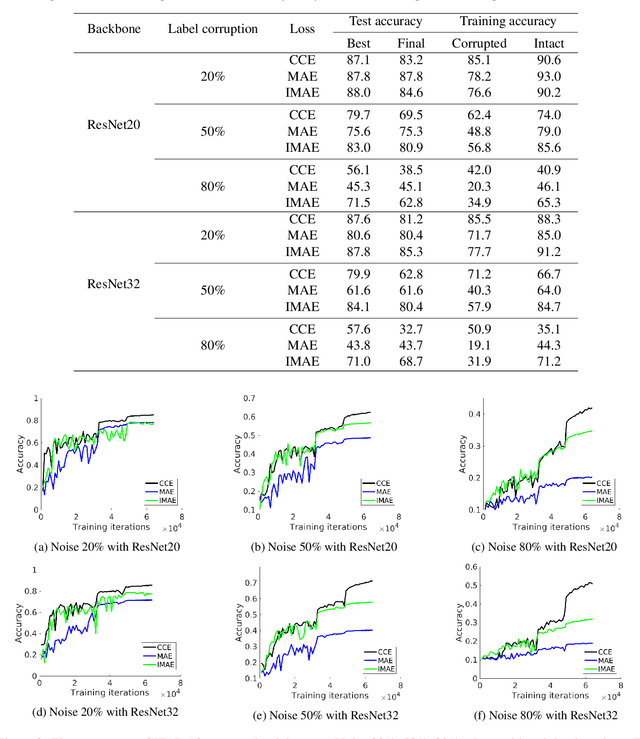
Label noise is inherent in many deep learning tasks when the training set becomes large. A typical approach to tackle noisy labels is using robust loss functions. Categorical cross entropy (CCE) is a successful loss function in many applications. However, CCE is also notorious for fitting samples with corrupted labels easily. In contrast, mean absolute error (MAE) is noise-tolerant theoretically, but it generally works much worse than CCE in practice. In this work, we have three main points. First, to explain why MAE generally performs much worse than CCE, we introduce a new understanding of them fundamentally by exposing their intrinsic sample weighting schemes from the perspective of every sample's gradient magnitude with respect to logit vector. Consequently, we find that MAE's differentiation degree over training examples is too small so that informative ones cannot contribute enough against the non-informative during training. Therefore, MAE generally underfits training data when noise rate is high. Second, based on our finding, we propose an improved MAE (IMAE), which inherits MAE's good noise-robustness. Moreover, the differentiation degree over training data points is controllable so that IMAE addresses the underfitting problem of MAE. Third, the effectiveness of IMAE against CCE and MAE is evaluated empirically with extensive experiments, which focus on image classification under synthetic corrupted labels and video retrieval under real noisy labels.