 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Joint Layer RNN based Keyphrase Extraction by Using Syntactical Features
Paper and Code
Sep 15, 2020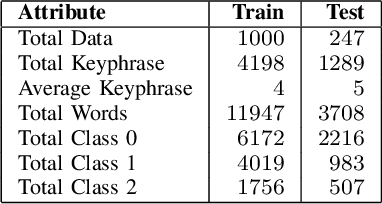
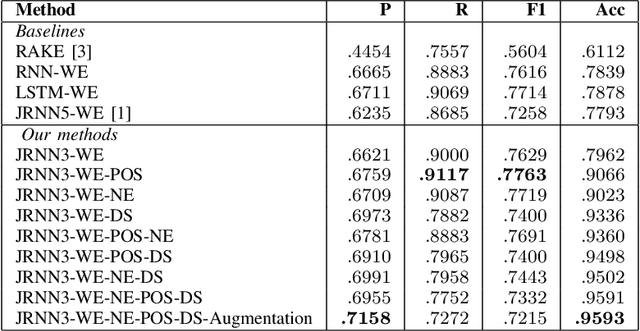
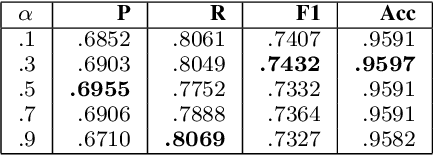
Keyphrase extraction as a task to identify important words or phrases from a text, is a crucial process to identify main topics when analyzing texts from a social media platform. In our study, we focus on text written in Indonesia language taken from Twitter. Different from the original joint layer recurrent neural network (JRNN) with output of one sequence of keywords and using only word embedding, here we propose to modify the input layer of JRNN to extract more than one sequence of keywords by additional information of syntactical features, namely part of speech, named entity types, and dependency structures. Since JRNN in general requires a large amount of data as the training examples and creating those examples is expensive, we used a data augmentation method to increase the number of training examples. Our experiment had shown that our method outperformed the baseline methods. Our method achieved .9597 in accuracy and .7691 in F1.