 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Generalization of Transfer Learning Across Domains Using Spatio-Temporal Features in Autonomous Driving
Paper and Code
Mar 15, 2021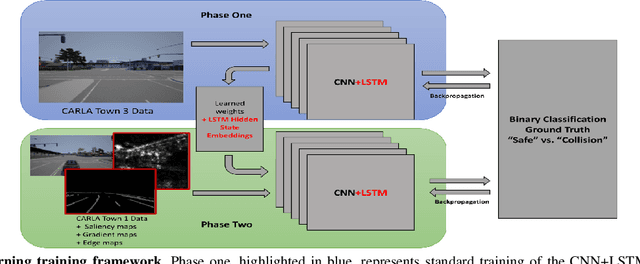
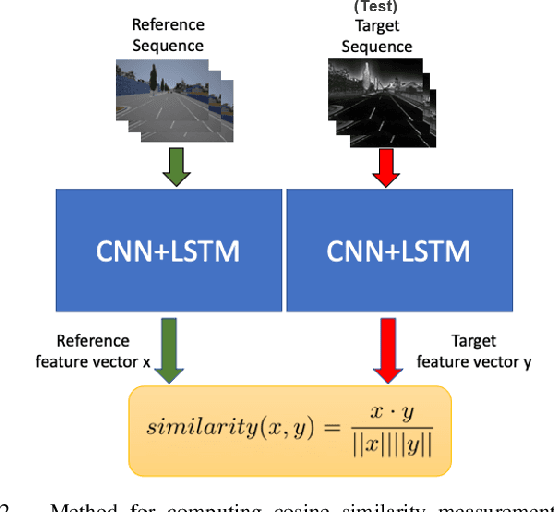

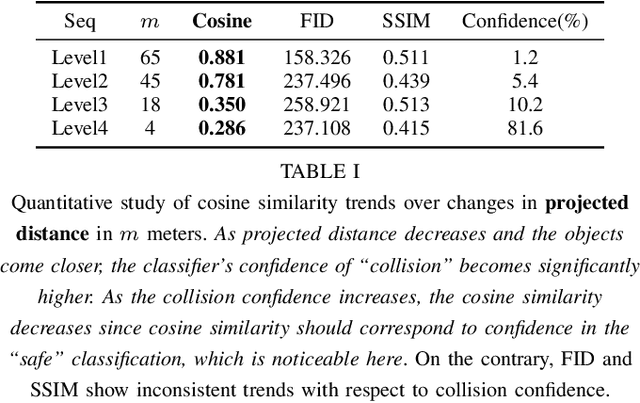
Training vision-based autonomous driving in the real world can be inefficient and impractical. Vehicle simulation can be used to learn in the virtual world, and the acquired skills can be transferred to handle real-world scenarios more effectively. Between virtual and real visual domains, common features such as relative distance to road edges and other vehicles over time are consistent. These visual elements are intuitively crucial for human decision making during driving. We hypothesize that these spatio-temporal factors can also be used in transfer learning to improve generalization across domains. First, we propose a CNN+LSTM transfer learning framework to extract the spatio-temporal features representing vehicle dynamics from scenes. Next, we conduct an ablation study to quantitatively estimate the significance of various features in the decisions of driving systems. We observe that physically interpretable factors are highly correlated with network decisions, while representational differences between scenes are not. Finally, based on the results of our ablation study, we propose a transfer learning pipeline that uses saliency maps and physical features extracted from a source model to enhance the performance of a target model. Training of our network is initialized with the learned weights from CNN and LSTM latent features (capturing the intrinsic physics of the moving vehicle w.r.t. its surroundings) transferred from one domain to another. Our experiments show that this proposed transfer learning framework better generalizes across unseen domains compared to a baseline CNN model on a binary classification learning task.