 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Dialogue Breakdown Detection with Semi-Supervised Learning
Paper and Code
Oct 30, 2020
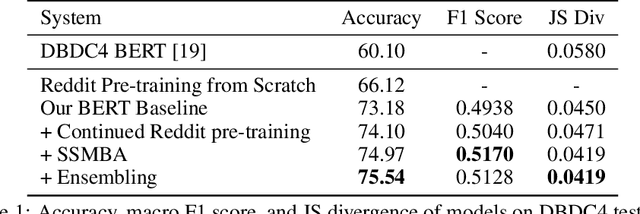
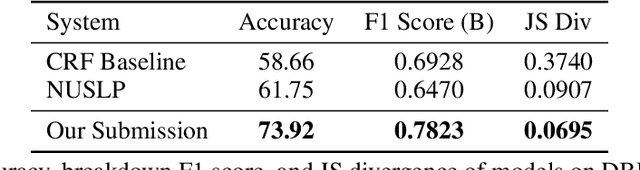
Building user trust in dialogue agents requires smooth and consistent dialogue exchanges. However, agents can easily lose conversational context and generate irrelevant utterances. These situations are called dialogue breakdown, where agent utterances prevent users from continuing the conversation. Building systems to detect dialogue breakdown allows agents to recover appropriately or avoid breakdown entirely. In this paper we investigate the use of semi-supervised learning methods to improve dialogue breakdown detection, including continued pre-training on the Reddit dataset and a manifold-based data augmentation method. We demonstrate the effectiveness of these methods on the Dialogue Breakdown Detection Challenge (DBDC) English shared task. Our submissions to the 2020 DBDC5 shared task place first, beating baselines and other submissions by over 12\% accuracy. In ablations on DBDC4 data from 2019, our semi-supervised learning methods improve the performance of a baseline BERT model by 2\% accuracy. These methods are applicable generally to any dialogue task and provide a simple way to improve model performance.