 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Cross-Lingual Reading Comprehension with Self-Training
Paper and Code
May 08, 2021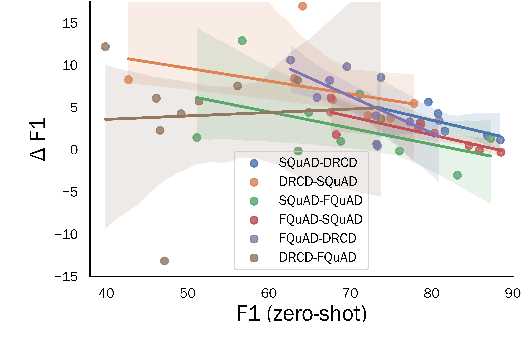

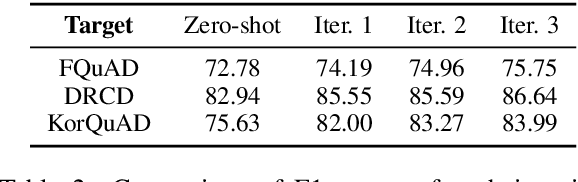
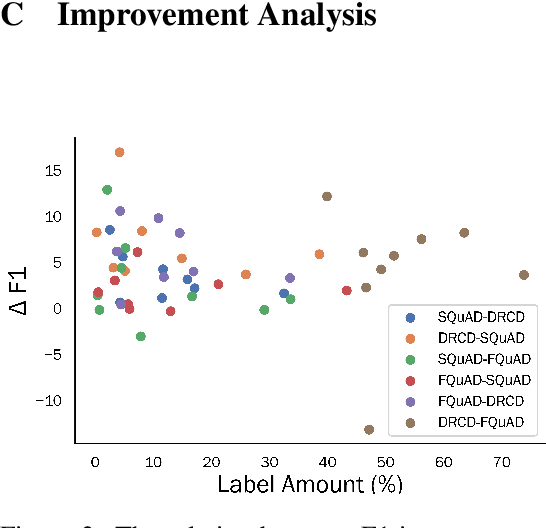
Substantial improvements have been made in machine reading comprehension, where the machine answers questions based on a given context. Current state-of-the-art models even surpass human performance on several benchmarks. However, their abilities in the cross-lingual scenario are still to be explored. Previous works have revealed the abilities of pre-trained multilingual models for zero-shot cross-lingual reading comprehension. In this paper, we further utilized unlabeled data to improve the performance. The model is first supervised-trained on source language corpus, and then self-trained with unlabeled target language data. The experiment results showed improvements for all languages, and we also analyzed how self-training benefits cross-lingual reading comprehension in qualitative aspects.