Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Code-switching Language Modeling with Artificially Generated Texts using Cycle-consistent Adversarial Networks
Paper and Code
Dec 12, 2021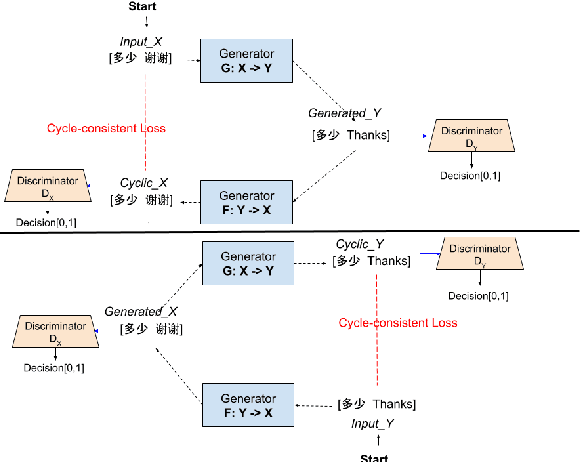
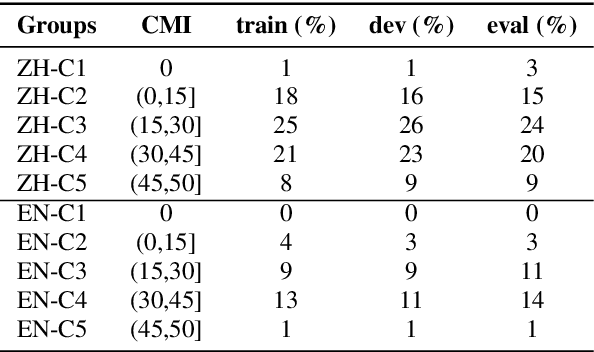
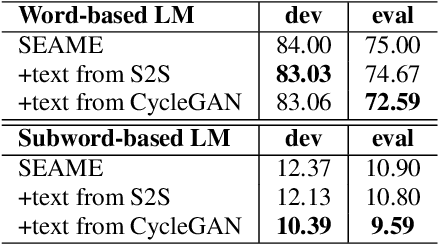

This paper presents our latest effort on improving Code-switching language models that suffer from data scarcity. We investigate methods to augment Code-switching training text data by artificially generating them. Concretely, we propose a cycle-consistent adversarial networks based framework to transfer monolingual text into Code-switching text, considering Code-switching as a speaking style. Our experimental results on the SEAME corpus show that utilising artificially generated Code-switching text data improves consistently the language model as well as the automatic speech recognition performance.
* 4 pages, 1 figure, Interspeech 2020
View paper on