 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved generalization by noise enhancement
Paper and Code
Sep 28, 2020
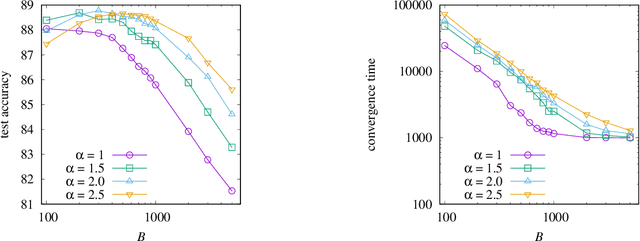
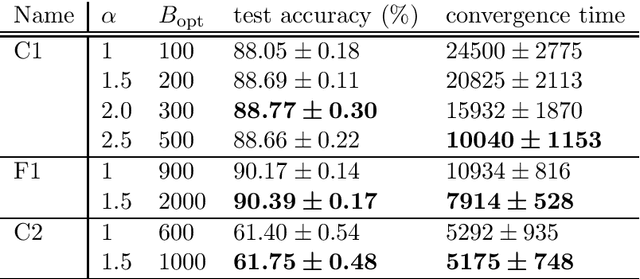
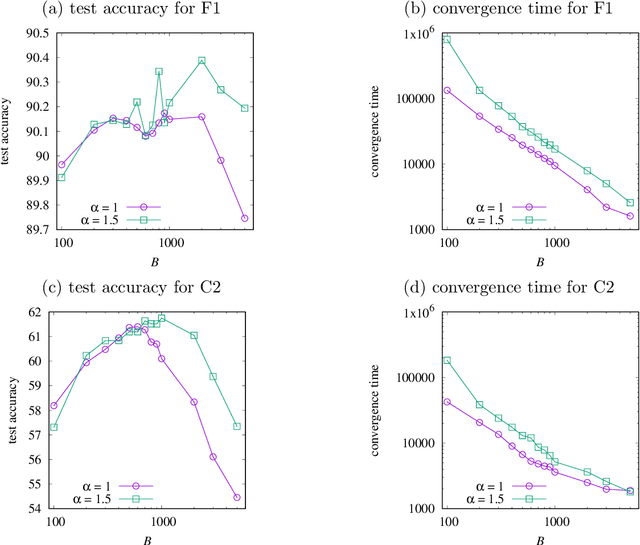
Recent studies have demonstrated that noise in stochastic gradient descent (SGD) is closely related to generalization: A larger SGD noise, if not too large, results in better generalization. Since the covariance of the SGD noise is proportional to $\eta^2/B$, where $\eta$ is the learning rate and $B$ is the minibatch size of SGD, the SGD noise has so far been controlled by changing $\eta$ and/or $B$. However, too large $\eta$ results in instability in the training dynamics and a small $B$ prevents scalable parallel computation. It is thus desirable to develop a method of controlling the SGD noise without changing $\eta$ and $B$. In this paper, we propose a method that achieves this goal using ``noise enhancement'', which is easily implemented in practice. We expound the underlying theoretical idea and demonstrate that the noise enhancement actually improves generalization for real datasets. It turns out that large-batch training with the noise enhancement even shows better generalization compared with small-batch training.