 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Analysis of Clipping Algorithms for Non-convex Optimization
Paper and Code
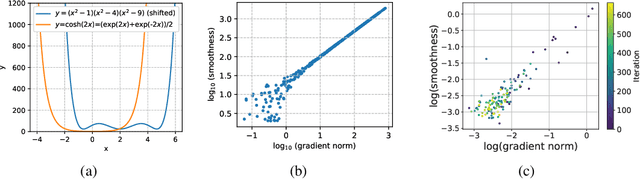

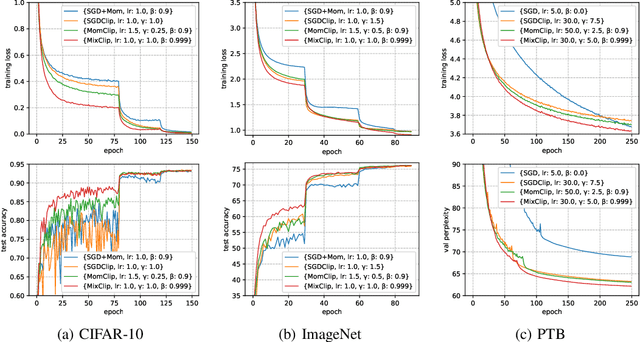
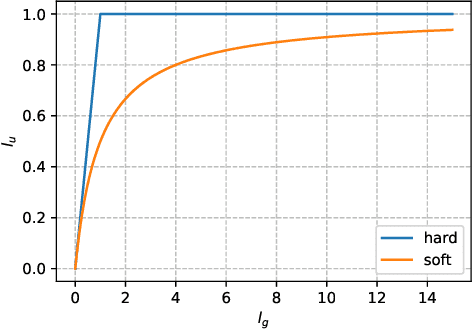
Gradient clipping is commonly used in training deep neural networks partly due to its practicability in relieving the exploding gradient problem. Recently, \citet{zhang2019gradient} show that clipped (stochastic) Gradient Descent (GD) converges faster than vanilla GD/SGD via introducing a new assumption called $(L_0, L_1)$-smoothness, which characterizes the violent fluctuation of gradients typically encountered in deep neural networks. However, their iteration complexities on the problem-dependent parameters are rather pessimistic, and theoretical justification of clipping combined with other crucial techniques, e.g. momentum acceleration, are still lacking. In this paper, we bridge the gap by presenting a general framework to study the clipping algorithms, which also takes momentum methods into consideration. We provide convergence analysis of the framework in both deterministic and stochastic setting, and demonstrate the tightness of our results by comparing them with existing lower bounds. Our results imply that the efficiency of clipping methods will not degenerate even in highly non-smooth regions of the landscape. Experiments confirm the superiority of clipping-based methods in deep learning tasks.