 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Algorithms for Bandit with Graph Feedback via Regret Decomposition
Paper and Code
May 30, 2022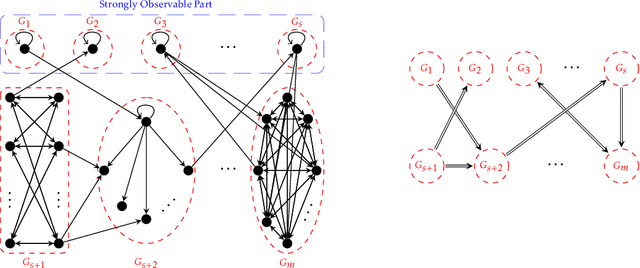
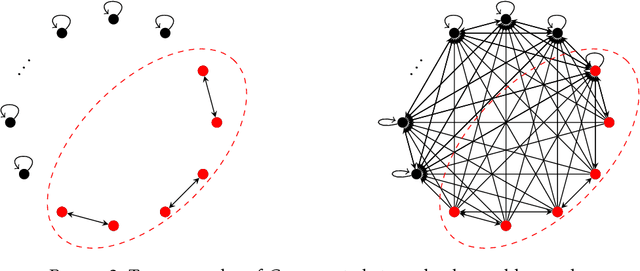
The problem of bandit with graph feedback generalizes both the multi-armed bandit (MAB) problem and the learning with expert advice problem by encoding in a directed graph how the loss vector can be observed in each round of the game. The mini-max regret is closely related to the structure of the feedback graph and their connection is far from being fully understood. We propose a new algorithmic framework for the problem based on a partition of the feedback graph. Our analysis reveals the interplay between various parts of the graph by decomposing the regret to the sum of the regret caused by small parts and the regret caused by their interaction. As a result, our algorithm can be viewed as an interpolation and generalization of the optimal algorithms for MAB and learning with expert advice. Our framework unifies previous algorithms for both strongly observable graphs and weakly observable graphs, resulting in improved and optimal regret bounds on a wide range of graph families including graphs of bounded degree and strongly observable graphs with a few corrupted arms.