Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Saliency in Deep Neural Networks
Paper and Code
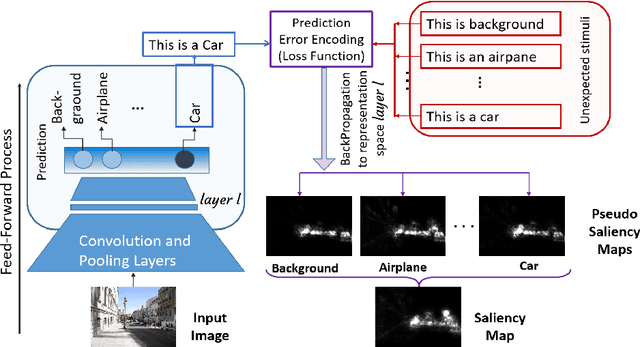



In this paper, we show that existing recognition and localization deep architectures, that have not been exposed to eye tracking data or any saliency datasets, are capable of predicting the human visual saliency. We term this as implicit saliency in deep neural networks. We calculate this implicit saliency using expectancy-mismatch hypothesis in an unsupervised fashion. Our experiments show that extracting saliency in this fashion provides comparable performance when measured against the state-of-art supervised algorithms. Additionally, the robustness outperforms those algorithms when we add large noise to the input images. Also, we show that semantic features contribute more than low-level features for human visual saliency detection.
View paper on