 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Compressibility of Overparametrized Neural Networks Trained with Heavy-Tailed SGD
Paper and Code
Jun 13, 2023
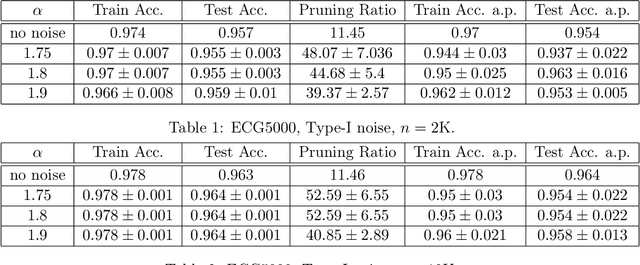
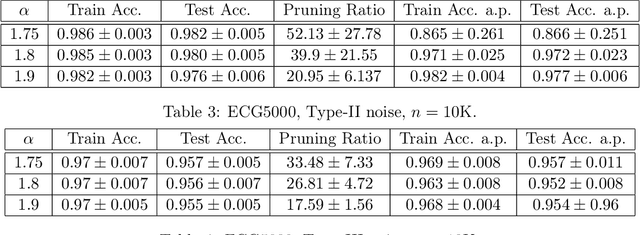

Neural network compression has been an increasingly important subject, due to its practical implications in terms of reducing the computational requirements and its theoretical implications, as there is an explicit connection between compressibility and the generalization error. Recent studies have shown that the choice of the hyperparameters of stochastic gradient descent (SGD) can have an effect on the compressibility of the learned parameter vector. Even though these results have shed some light on the role of the training dynamics over compressibility, they relied on unverifiable assumptions and the resulting theory does not provide a practical guideline due to its implicitness. In this study, we propose a simple modification for SGD, such that the outputs of the algorithm will be provably compressible without making any nontrivial assumptions. We consider a one-hidden-layer neural network trained with SGD and we inject additive heavy-tailed noise to the iterates at each iteration. We then show that, for any compression rate, there exists a level of overparametrization (i.e., the number of hidden units), such that the output of the algorithm will be compressible with high probability. To achieve this result, we make two main technical contributions: (i) we build on a recent study on stochastic analysis and prove a 'propagation of chaos' result with improved rates for a class of heavy-tailed stochastic differential equations, and (ii) we derive strong-error estimates for their Euler discretization. We finally illustrate our approach on experiments, where the results suggest that the proposed approach achieves compressibility with a slight compromise from the training and test error.