 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplementing Randomized Matrix Algorithms in Parallel and Distributed Environments
Paper and Code
Jul 27, 2015
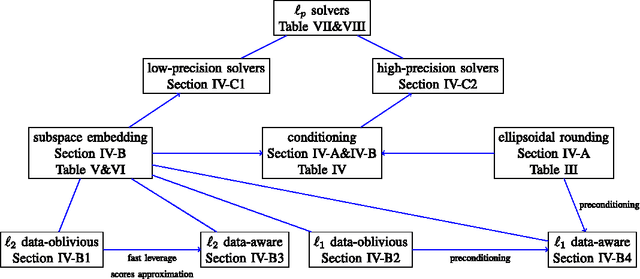


In this era of large-scale data, distributed systems built on top of clusters of commodity hardware provide cheap and reliable storage and scalable processing of massive data. Here, we review recent work on developing and implementing randomized matrix algorithms in large-scale parallel and distributed environments. Randomized algorithms for matrix problems have received a great deal of attention in recent years, thus far typically either in theory or in machine learning applications or with implementations on a single machine. Our main focus is on the underlying theory and practical implementation of random projection and random sampling algorithms for very large very overdetermined (i.e., overconstrained) $\ell_1$ and $\ell_2$ regression problems. Randomization can be used in one of two related ways: either to construct sub-sampled problems that can be solved, exactly or approximately, with traditional numerical methods; or to construct preconditioned versions of the original full problem that are easier to solve with traditional iterative algorithms. Theoretical results demonstrate that in near input-sparsity time and with only a few passes through the data one can obtain very strong relative-error approximate solutions, with high probability. Empirical results highlight the importance of various trade-offs (e.g., between the time to construct an embedding and the conditioning quality of the embedding, between the relative importance of computation versus communication, etc.) and demonstrate that $\ell_1$ and $\ell_2$ regression problems can be solved to low, medium, or high precision in existing distributed systems on up to terabyte-sized data.