 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of Decoding Methods on Human Alignment of Conversational LLMs
Paper and Code
Jul 28, 2024


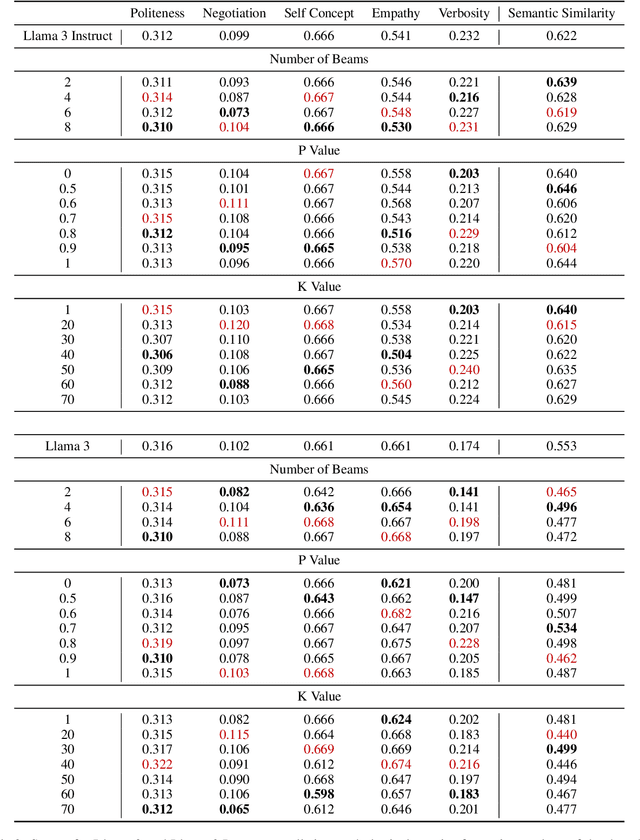
To be included into chatbot systems, Large language models (LLMs) must be aligned with human conversational conventions. However, being trained mainly on web-scraped data gives existing LLMs a voice closer to informational text than actual human speech. In this paper, we examine the effect of decoding methods on the alignment between LLM-generated and human conversations, including Beam Search, Top K Sampling, and Nucleus Sampling. We present new measures of alignment in substance, style, and psychometric orientation, and experiment with two conversation datasets. Our results provide subtle insights: better alignment is attributed to fewer beams in Beam Search and lower values of P in Nucleus Sampling. We also find that task-oriented and open-ended datasets perform differently in terms of alignment, indicating the significance of taking into account the context of the interaction.