 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImitation from Arbitrary Experience: A Dual Unification of Reinforcement and Imitation Learning Methods
Paper and Code
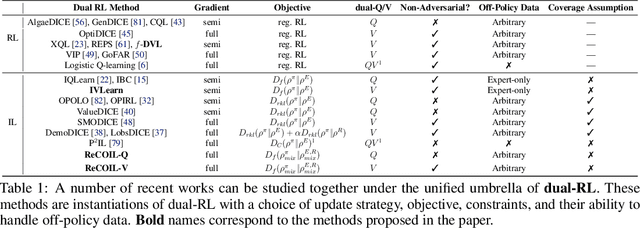

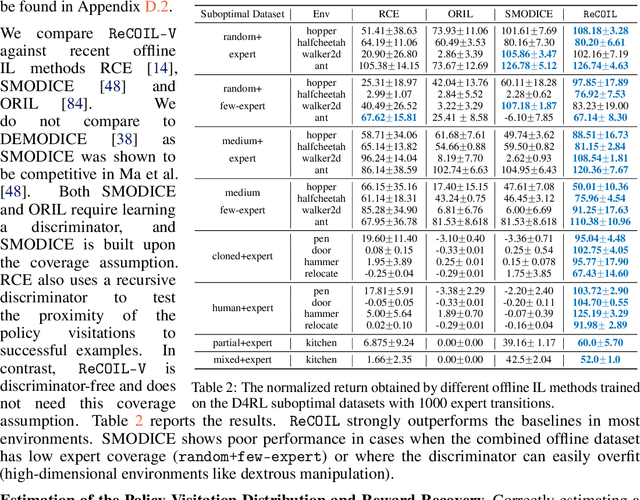
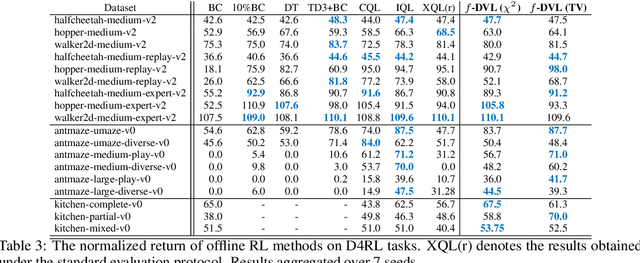
It is well known that Reinforcement Learning (RL) can be formulated as a convex program with linear constraints. The dual form of this formulation is unconstrained, which we refer to as dual RL, and can leverage preexisting tools from convex optimization to improve the learning performance of RL agents. We show that several state-of-the-art deep RL algorithms (in online, offline, and imitation settings) can be viewed as dual RL approaches in a unified framework. This unification calls for the methods to be studied on common ground, so as to identify the components that actually contribute to the success of these methods. Our unification also reveals that prior off-policy imitation learning methods in the dual space are based on an unrealistic coverage assumption and are restricted to matching a particular f-divergence. We propose a new method using a simple modification to the dual framework that allows for imitation learning with arbitrary off-policy data to obtain near-expert performance.