 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImitating Deep Learning Dynamics via Locally Elastic Stochastic Differential Equations
Paper and Code

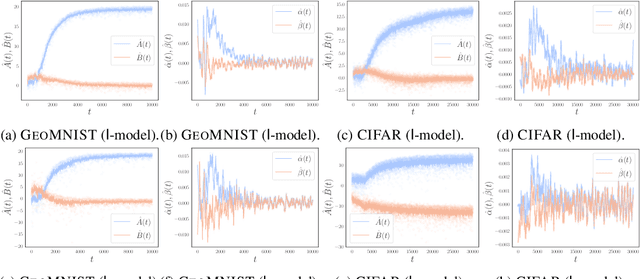


Understanding the training dynamics of deep learning models is perhaps a necessary step toward demystifying the effectiveness of these models. In particular, how do data from different classes gradually become separable in their feature spaces when training neural networks using stochastic gradient descent? In this study, we model the evolution of features during deep learning training using a set of stochastic differential equations (SDEs) that each corresponds to a training sample. As a crucial ingredient in our modeling strategy, each SDE contains a drift term that reflects the impact of backpropagation at an input on the features of all samples. Our main finding uncovers a sharp phase transition phenomenon regarding the {intra-class impact: if the SDEs are locally elastic in the sense that the impact is more significant on samples from the same class as the input, the features of the training data become linearly separable, meaning vanishing training loss; otherwise, the features are not separable, regardless of how long the training time is. Moreover, in the presence of local elasticity, an analysis of our SDEs shows that the emergence of a simple geometric structure called the neural collapse of the features. Taken together, our results shed light on the decisive role of local elasticity in the training dynamics of neural networks. We corroborate our theoretical analysis with experiments on a synthesized dataset of geometric shapes and CIFAR-10.