 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Translation for Medical Image Generation -- Ischemic Stroke Lesions
Paper and Code
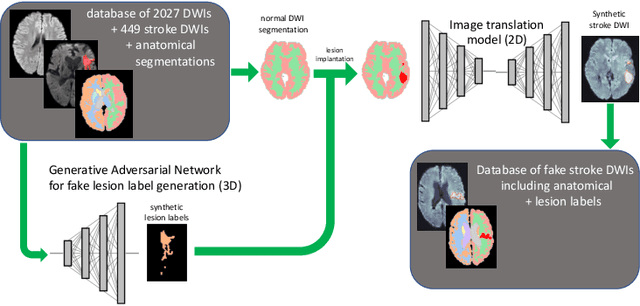
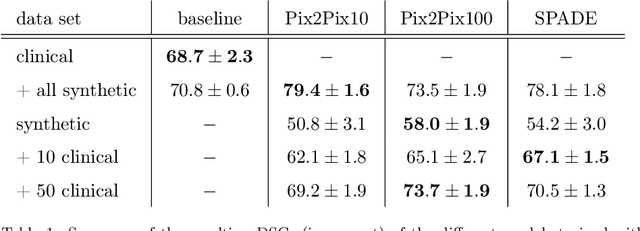
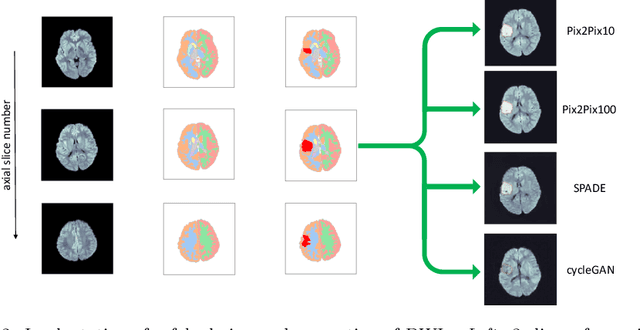
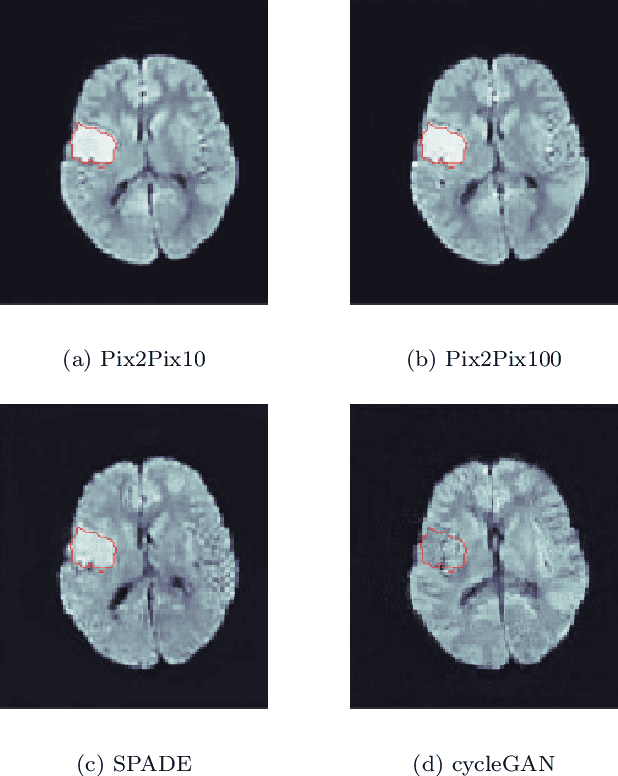
Deep learning-based automated disease detection and segmentation algorithms promise to accelerate and improve many clinical processes. However, such algorithms require vast amounts of annotated training data, which are typically not available in a medical context, e.g., due to data privacy concerns, legal obstructions, and non-uniform data formats. Synthetic databases of annotated pathologies could provide the required amounts of training data. Here, we demonstrate with the example of ischemic stroke that a significant improvement in lesion segmentation is feasible using deep learning-based data augmentation. To this end, we train different image-to-image translation models to synthesize diffusion-weighted magnetic resonance images (DWIs) of brain volumes with and without stroke lesions from semantic segmentation maps. In addition, we train a generative adversarial network to generate synthetic lesion masks. Subsequently, we combine these two components to build a large database of synthetic stroke DWIs. The performance of the various generative models is evaluated using a U-Net which is trained to segment stroke lesions on a clinical test set. We compare the results to human expert inter-reader scores. For the model with the best performance, we report a maximum Dice score of 82.6\%, which significantly outperforms the model trained on the clinical images alone (74.8\%), and also the inter-reader Dice score of two human readers of 76.9\%. Moreover, we show that for a very limited database of only 10 or 50 clinical cases, synthetic data can be used to pre-train the segmentation algorithms, which ultimately yields an improvement by a factor of as high as 8 compared to a setting where no synthetic data is used.