 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Matters: A New Dataset and Empirical Study for Multimodal Hyperbole Detection
Paper and Code

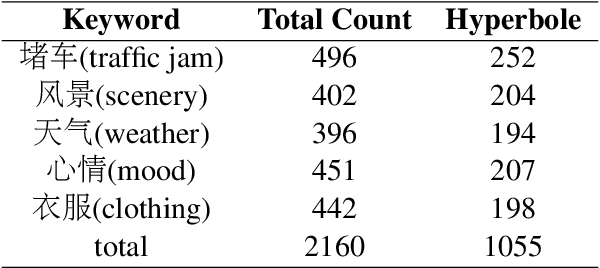


Hyperbole, or exaggeration, is a common linguistic phenomenon. The detection of hyperbole is an important part of understanding human expression. There have been several studies on hyperbole detection, but most of which focus on text modality only. However, with the development of social media, people can create hyperbolic expressions with various modalities, including text, images, videos, etc. In this paper, we focus on multimodal hyperbole detection. We create a multimodal detection dataset\footnote{The dataset will be released to the community.} from Weibo (a Chinese social media) and carry out some studies on it. We treat the text and image from a piece of weibo as two modalities and explore the role of text and image for hyperbole detection. Different pre-trained multimodal encoders are also evaluated on this downstream task to show their performance. Besides, since this dataset is constructed from five different topics, we also evaluate the cross-domain performance of different models. These studies can serve as a benchmark and point out the direction of further study on multimodal hyperbole detection.