 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage classification using quantum inference on the D-Wave 2X
Paper and Code
May 28, 2019
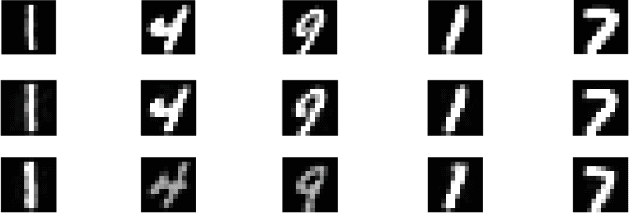
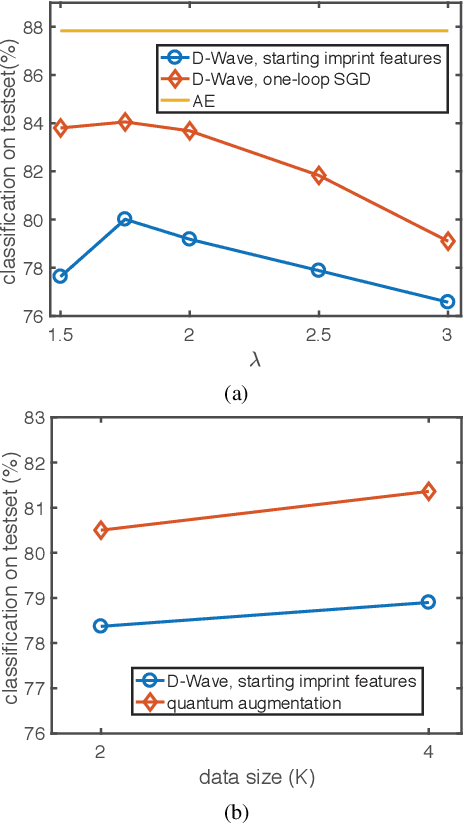
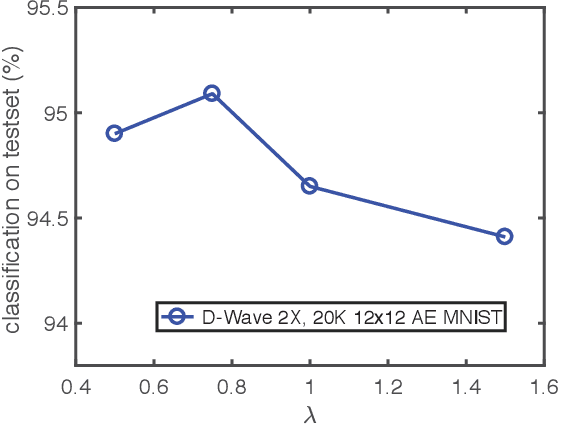
We use a quantum annealing D-Wave 2X computer to obtain solutions to NP-hard sparse coding problems. To reduce the dimensionality of the sparse coding problem to fit on the quantum D-Wave 2X hardware, we passed downsampled MNIST images through a bottleneck autoencoder. To establish a benchmark for classification performance on this reduced dimensional data set, we used an AlexNet-like architecture implemented in TensorFlow, obtaining a classification score of $94.54 \pm 0.7 \%$. As a control, we showed that the same AlexNet-like architecture produced near-state-of-the-art classification performance $(\sim 99\%)$ on the original MNIST images. To obtain a set of optimized features for inferring sparse representations of the reduced dimensional MNIST dataset, we imprinted on a random set of $47$ image patches followed by an off-line unsupervised learning algorithm using stochastic gradient descent to optimize for sparse coding. Our single-layer of sparse coding matched the stride and patch size of the first convolutional layer of the AlexNet-like deep neural network and contained $47$ fully-connected features, $47$ being the maximum number of dictionary elements that could be embedded onto the D-Wave $2$X hardware. Recent work suggests that the optimal level of sparsity corresponds to a critical value of the trade-off parameter associated with a putative second order phase transition, an observation supported by a free energy analysis of D-Wave energy states. When the sparse representations inferred by the D-Wave $2$X were passed to a linear support vector machine, we obtained a classification score of $95.68\%$. Thus, on this problem, we find that a single-layer of quantum inference is able to outperform a standard deep neural network architecture.