 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Invariant Texture Violation for Robust Deepfake Detection
Paper and Code
Dec 19, 2020

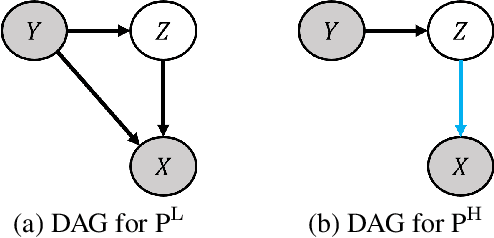
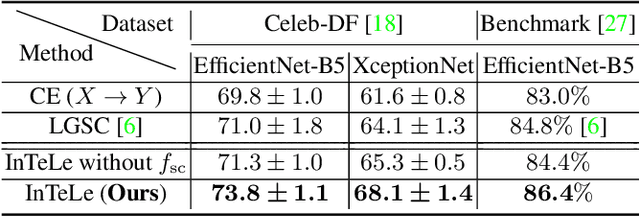
Existing deepfake detection methods have reported promising in-distribution results, by accessing published large-scale dataset. However, due to the non-smooth synthesis method, the fake samples in this dataset may expose obvious artifacts (e.g., stark visual contrast, non-smooth boundary), which were heavily relied on by most of the frame-level detection methods above. As these artifacts do not come up in real media forgeries, the above methods can suffer from a large degradation when applied to fake images that close to reality. To improve the robustness for high-realism fake data, we propose the Invariant Texture Learning (InTeLe) framework, which only accesses the published dataset with low visual quality. Our method is based on the prior that the microscopic facial texture of the source face is inevitably violated by the texture transferred from the target person, which can hence be regarded as the invariant characterization shared among all fake images. To learn such an invariance for deepfake detection, our InTeLe introduces an auto-encoder framework with different decoders for pristine and fake images, which are further appended with a shallow classifier in order to separate out the obvious artifact-effect. Equipped with such a separation, the extracted embedding by encoder can capture the texture violation in fake images, followed by the classifier for the final pristine/fake prediction. As a theoretical guarantee, we prove the identifiability of such an invariance texture violation, i.e., to be precisely inferred from observational data. The effectiveness and utility of our method are demonstrated by promising generalization ability from low-quality images with obvious artifacts to fake images with high realism.