 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying and Harnessing the Building Blocks of Machine Learning Pipelines for Sensible Initialization of a Data Science Automation Tool
Paper and Code


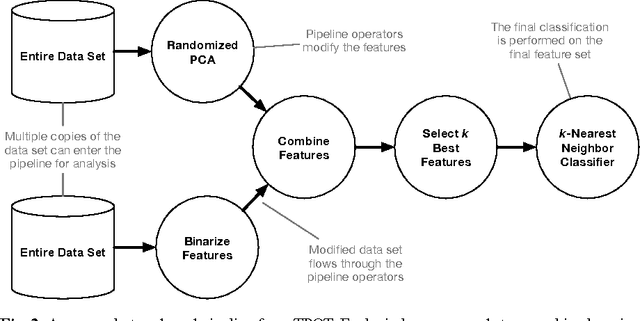

As data science continues to grow in popularity, there will be an increasing need to make data science tools more scalable, flexible, and accessible. In particular, automated machine learning (AutoML) systems seek to automate the process of designing and optimizing machine learning pipelines. In this chapter, we present a genetic programming-based AutoML system called TPOT that optimizes a series of feature preprocessors and machine learning models with the goal of maximizing classification accuracy on a supervised classification problem. Further, we analyze a large database of pipelines that were previously used to solve various supervised classification problems and identify 100 short series of machine learning operations that appear the most frequently, which we call the building blocks of machine learning pipelines. We harness these building blocks to initialize TPOT with promising solutions, and find that this sensible initialization method significantly improves TPOT's performance on one benchmark at no cost of significantly degrading performance on the others. Thus, sensible initialization with machine learning pipeline building blocks shows promise for GP-based AutoML systems, and should be further refined in future work.