 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentification of Pediatric Sepsis Subphenotypes for Enhanced Machine Learning Predictive Performance: A Latent Profile Analysis
Paper and Code
Aug 23, 2019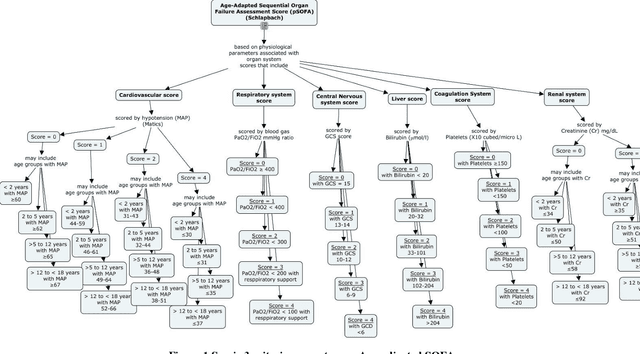
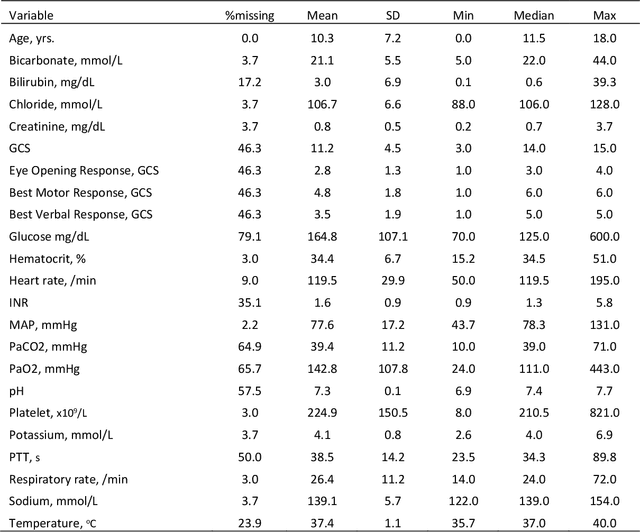
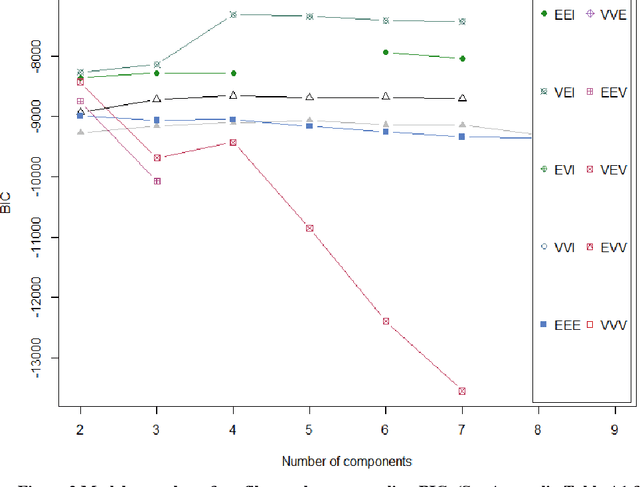
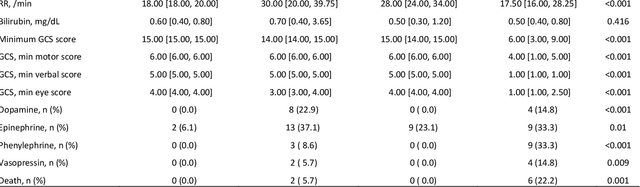
Background: While machine learning (ML) models are rapidly emerging as promising screening tools in critical care medicine, the identification of homogeneous subphenotypes within populations with heterogeneous conditions such as pediatric sepsis may facilitate attainment of high-predictive performance of these prognostic algorithms. This study is aimed to identify subphenotypes of pediatric sepsis and demonstrate the potential value of partitioned data/subtyping-based training. Methods: This was a retrospective study of clinical data extracted from medical records of 6,446 pediatric patients that were admitted at a major hospital system in the DC area. Vitals and labs associated with patients meeting the diagnostic criteria for sepsis were used to perform latent profile analysis. Modern ML algorithms were used to explore the predictive performance benefits of reduced training data heterogeneity via label profiling. Results: In total 134 (2.1%) patients met the diagnostic criteria for sepsis in this cohort and latent profile analysis identified four profiles/subphenotypes of pediatric sepsis. Profiles 1 and 3 had the lowest mortality and included pediatric patients from different age groups. Profile 2 were characterized by respiratory dysfunction; profile 4 by neurological dysfunction and highest mortality rate (22.2%). Machine learning experiments comparing the predictive performance of models derived without training data profiling against profile targeted models suggest statistically significant improved performance of prediction can be obtained. For example, area under ROC curve (AUC) obtained to predict profile 4 with 24-hour data (AUC = .998, p < .0001) compared favorably with the AUC obtained from the model considering all profiles as a single homogeneous group (AUC = .918) with 24-hour data.