 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeID-aware Quality for Set-based Person Re-identification
Paper and Code

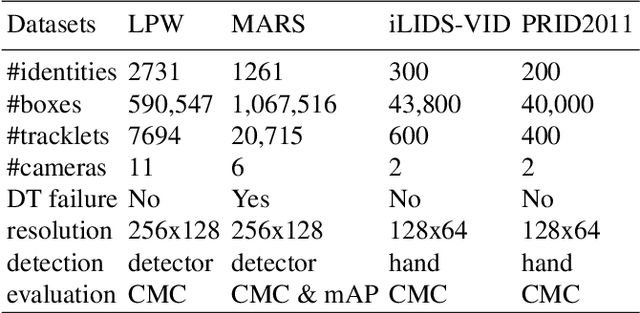
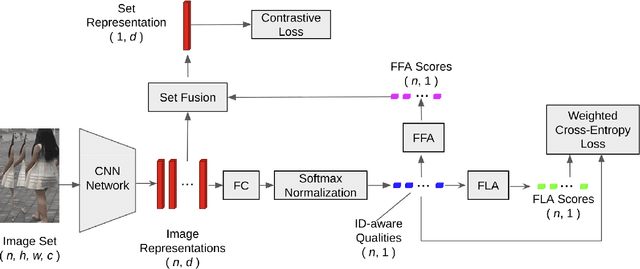
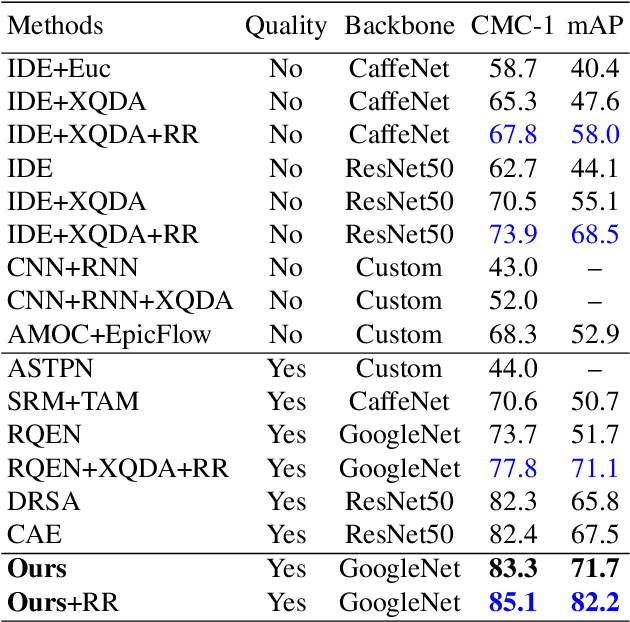
Set-based person re-identification (SReID) is a matching problem that aims to verify whether two sets are of the same identity (ID). Existing SReID models typically generate a feature representation per image and aggregate them to represent the set as a single embedding. However, they can easily be perturbed by noises--perceptually/semantically low quality images--which are inevitable due to imperfect tracking/detection systems, or overfit to trivial images. In this work, we present a novel and simple solution to this problem based on ID-aware quality that measures the perceptual and semantic quality of images guided by their ID information. Specifically, we propose an ID-aware Embedding that consists of two key components: (1) Feature learning attention that aims to learn robust image embeddings by focusing on 'medium' hard images. This way it can prevent overfitting to trivial images, and alleviate the influence of outliers. (2) Feature fusion attention is to fuse image embeddings in the set to obtain the set-level embedding. It ignores noisy information and pays more attention to discriminative images to aggregate more discriminative information. Experimental results on four datasets show that our method outperforms state-of-the-art approaches despite the simplicity of our approach.