 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICMSC: Intra- and Cross-modality Semantic Consistency for Unsupervised Domain Adaptation on Hip Joint Bone Segmentation
Paper and Code
Dec 23, 2020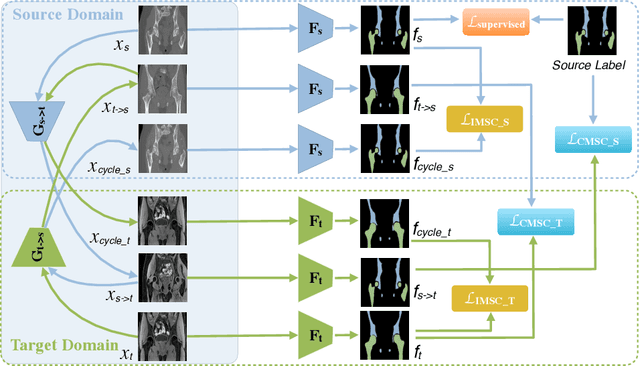
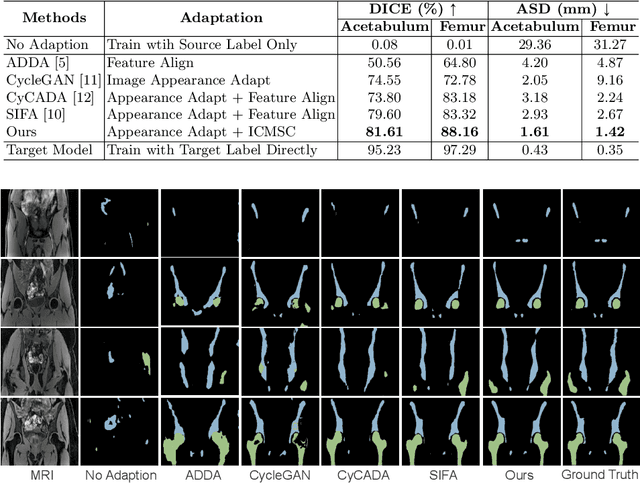
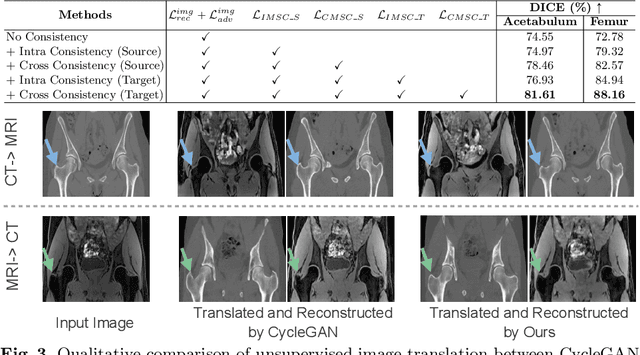
Unsupervised domain adaptation (UDA) for cross-modality medical image segmentation has shown great progress by domain-invariant feature learning or image appearance translation. Adapted feature learning usually cannot detect domain shifts at the pixel level and is not able to achieve good results in dense semantic segmentation tasks. Image appearance translation, e.g. CycleGAN, translates images into different styles with good appearance, despite its population, its semantic consistency is hardly to maintain and results in poor cross-modality segmentation. In this paper, we propose intra- and cross-modality semantic consistency (ICMSC) for UDA and our key insight is that the segmentation of synthesised images in different styles should be consistent. Specifically, our model consists of an image translation module and a domain-specific segmentation module. The image translation module is a standard CycleGAN, while the segmentation module contains two domain-specific segmentation networks. The intra-modality semantic consistency (IMSC) forces the reconstructed image after a cycle to be segmented in the same way as the original input image, while the cross-modality semantic consistency (CMSC) encourages the synthesized images after translation to be segmented exactly the same as before translation. Comprehensive experimental results on cross-modality hip joint bone segmentation show the effectiveness of our proposed method, which achieves an average DICE of 81.61% on the acetabulum and 88.16% on the proximal femur, outperforming other state-of-the-art methods. It is worth to note that without UDA, a model trained on CT for hip joint bone segmentation is non-transferable to MRI and has almost zero-DICE segmentation.