 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypothesis Testing for Automated Community Detection in Networks
Paper and Code
Nov 20, 2013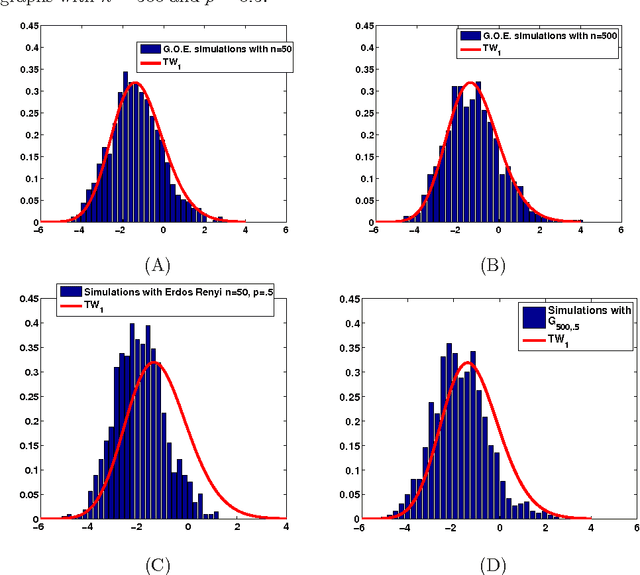
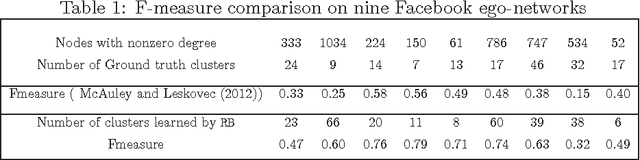

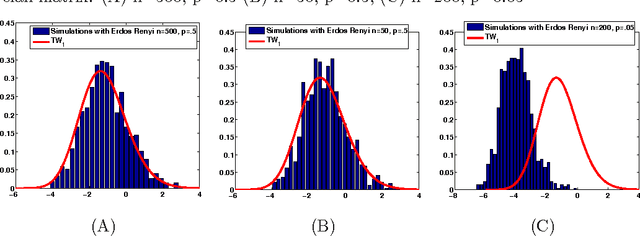
Community detection in networks is a key exploratory tool with applications in a diverse set of areas, ranging from finding communities in social and biological networks to identifying link farms in the World Wide Web. The problem of finding communities or clusters in a network has received much attention from statistics, physics and computer science. However, most clustering algorithms assume knowledge of the number of clusters k. In this paper we propose to automatically determine k in a graph generated from a Stochastic Blockmodel. Our main contribution is twofold; first, we theoretically establish the limiting distribution of the principal eigenvalue of the suitably centered and scaled adjacency matrix, and use that distribution for our hypothesis test. Secondly, we use this test to design a recursive bipartitioning algorithm. Using quantifiable classification tasks on real world networks with ground truth, we show that our algorithm outperforms existing probabilistic models for learning overlapping clusters, and on unlabeled networks, we show that we uncover nested community structure.