 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperspherical Quantization: Toward Smaller and More Accurate Models
Paper and Code
Dec 24, 2022


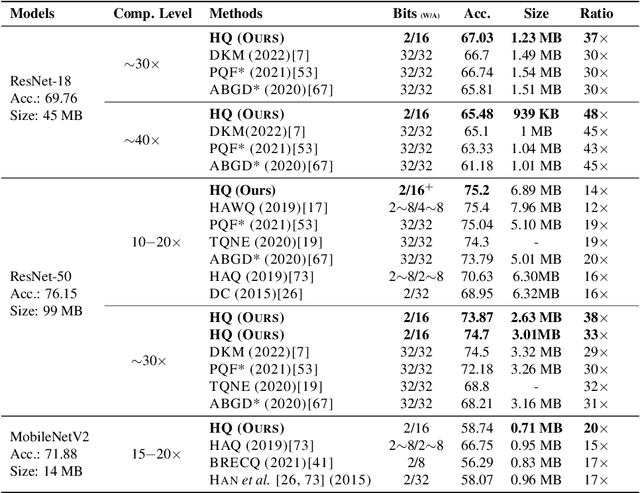
Model quantization enables the deployment of deep neural networks under resource-constrained devices. Vector quantization aims at reducing the model size by indexing model weights with full-precision embeddings, i.e., codewords, while the index needs to be restored to 32-bit during computation. Binary and other low-precision quantization methods can reduce the model size up to 32$\times$, however, at the cost of a considerable accuracy drop. In this paper, we propose an efficient framework for ternary quantization to produce smaller and more accurate compressed models. By integrating hyperspherical learning, pruning and reinitialization, our proposed Hyperspherical Quantization (HQ) method reduces the cosine distance between the full-precision and ternary weights, thus reducing the bias of the straight-through gradient estimator during ternary quantization. Compared with existing work at similar compression levels ($\sim$30$\times$, $\sim$40$\times$), our method significantly improves the test accuracy and reduces the model size.