 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperDPO: Hypernetwork-based Multi-Objective Fine-Tuning Framework
Paper and Code
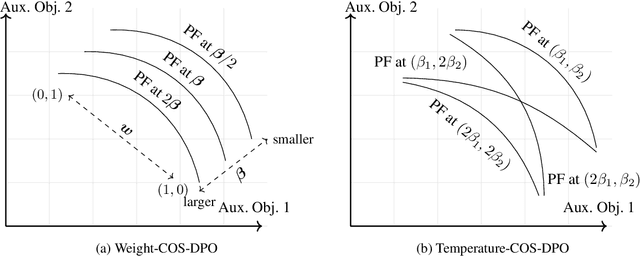
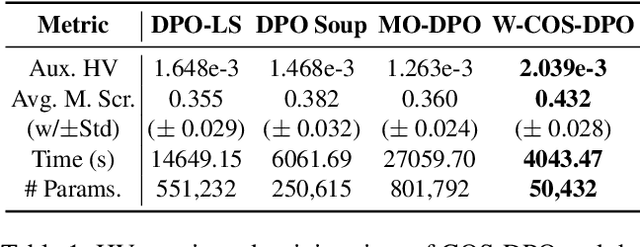
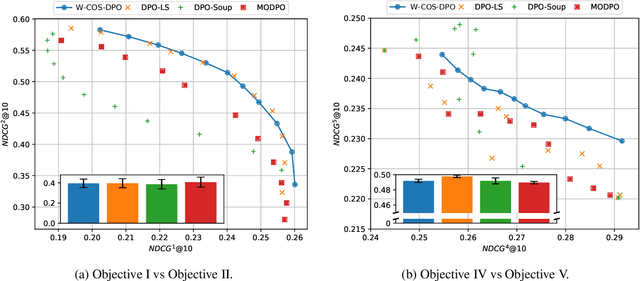
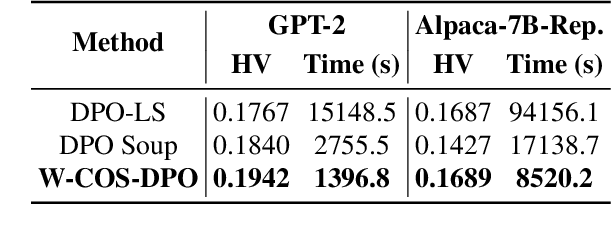
In LLM alignment and many other ML applications, one often faces the Multi-Objective Fine-Tuning (MOFT) problem, i.e. fine-tuning an existing model with datasets labeled w.r.t. different objectives simultaneously. To address the challenge, we propose the HyperDPO framework, a hypernetwork-based approach that extends the Direct Preference Optimization (DPO) technique, originally developed for efficient LLM alignment with preference data, to accommodate the MOFT settings. By substituting the Bradley-Terry-Luce model in DPO with the Plackett-Luce model, our framework is capable of handling a wide range of MOFT tasks that involve listwise ranking datasets. Compared with previous approaches, HyperDPO enjoys an efficient one-shot training process for profiling the Pareto front of auxiliary objectives, and offers flexible post-training control over trade-offs. Additionally, we propose a novel Hyper Prompt Tuning design, that conveys continuous weight across objectives to transformer-based models without altering their architecture. We demonstrate the effectiveness and efficiency of the HyperDPO framework through its applications to various tasks, including Learning-to-Rank (LTR) and LLM alignment, highlighting its viability for large-scale ML deployments.