 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyper-Class Representation of Data
Paper and Code
Jan 28, 2022
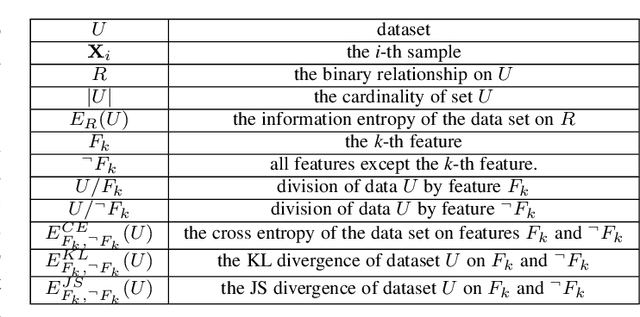
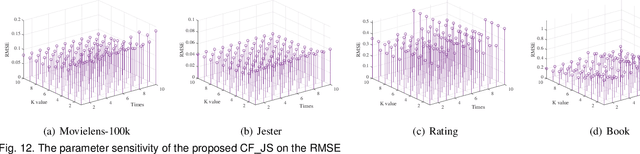
Data representation is often of the natural form with their attribute values. To utilize the data efficiently, one needs to well understand the observed attribute values and identify the potential useful information in the data/smaples, or training data. In this paper, a new data representation, named as hyper-classes representation, is proposed for improving recommendation. At first, the cross entropy, KL divergence and JS divergence of features in data are defined. And then, the hyper-classes in data can be discovered with these three parameters. Finally, a kind of recommendation algorithm is used to evaluate the proposed hyper-class representation of data, and shows that the hyper-class representation is able to provide truly useful reference information for recommendation systems and makes recommendations much better than existing algorithms, i.e., this approach is efficient and promising.