 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid-Regressive Neural Machine Translation
Paper and Code

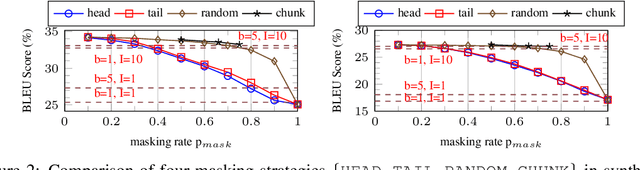
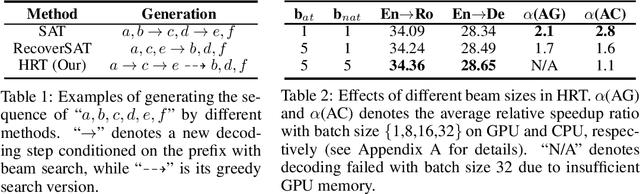

In this work, we empirically confirm that non-autoregressive translation with an iterative refinement mechanism (IR-NAT) suffers from poor acceleration robustness because it is more sensitive to decoding batch size and computing device setting than autoregressive translation (AT). Inspired by it, we attempt to investigate how to combine the strengths of autoregressive and non-autoregressive translation paradigms better. To this end, we demonstrate through synthetic experiments that prompting a small number of AT's predictions can promote one-shot non-autoregressive translation to achieve the equivalent performance of IR-NAT. Following this line, we propose a new two-stage translation prototype called hybrid-regressive translation (HRT). Specifically, HRT first generates discontinuous sequences via autoregression (e.g., make a prediction every k tokens, k>1) and then fills in all previously skipped tokens at once in a non-autoregressive manner. We also propose a bag of techniques to effectively and efficiently train HRT without adding any model parameters. HRT achieves the state-of-the-art BLEU score of 28.49 on the WMT En-De task and is at least 1.5x faster than AT, regardless of batch size and device. In addition, another bonus of HRT is that it successfully inherits the good characteristics of AT in the deep-encoder-shallow-decoder architecture. Concretely, compared to the vanilla HRT with a 6-layer encoder and 6-layer decoder, the inference speed of HRT with a 12-layer encoder and 1-layer decoder is further doubled on both GPU and CPU without BLEU loss.